.jpeg)
Predictive Analysis of Credit Risk Using Non-Financial Information via Machine Learning: Focusing on ESG Performance, Analyst Coverage, and Carbon Emission Information
1 Hanyang University
2 Gyeong-In National University of Education
DOI: https://doi.org/10.17287/kbr.2025.29.4.75
Abstract
Previous research has inadequately explained the relationship between non-financial information and credit risk due to the selective assignment of credit ratings to firms. This study addresses this limitation by employing machine learning techniques trained on firms’ past credit ratings and using the resulting variable as a control to analyze the relationship between non-financial factors and credit risk, measured by the distance to default (DD). The key findings of this study are as follows. First, using a sample of involuntarily delisted firms, we confirm that our trained machine learning model effectively captures default patterns. Second, we find that governance (G) among ESG factors significantly reduces default probability. In contrast, social (S) factor, analyst coverage, and carbon emissions do not show a significant relationship with DD. This study makes several contributions. First, by employing a machine learning framework, our research extends beyond the traditional focus on bond-issuing firms. Second, we highlight that specific ESG factors, particularly governance (G), should be incorporated into credit rating assessments along with traditional financial indicators. Third, our research provides an analytical framework for examining the relationship between involuntarily delisted firms and their financial performance.
Ⅰ. 서 론
신용평가는 기업의 채무상환능력을 평가하여 이를 등급화하는 과정이다. 신용 평가는 기업의 재무 정보에 기초한 재무 평가, 수치적인 계량화가 어려운 비(非)재무적 요소에 대한 평가로 구분된다. 이러한 정보를 기반으로 신용평가사는 채권 발행기업의 사업 위험, 재무 위험, 발행 조건을 다각적으로 검토하여 해당 기업의 신용등급을 결정한다. 또한 신용평가는 투자자와 발행기업, 궁극적으로 금융시장 전반에 대하여 기능을 수행하는 자본시장의 핵심 요소라고 할 수 있다. 투자사는 투자에 따른 리스크를 줄이기 위한 자료를 제공함으로써 미래 불확실성을 줄이고, 투자 의사결정에 따른 비용을 줄일 수 있다. 반면 발행 회사 입장에서는 자사의 신용도를 고려한 자금조달 계획을 수립함으로써 대외 신뢰도를 올릴 수 있다. 궁극적으로 신용평가는 금융시장 전반으로 중개 비용을 줄여나감에 따라 국가 경제의 효율성을 개선시키는 기능을 한다고 볼 수 있다.
국내 학계에서 금융·자본 데이터 분석과 이에 기초한 비즈니스 결정 과정이 중요하게 여겨지고 있다(송성환 외, 2017; 서문석과 김동호, 2019; 서민교, 2013; 윤보현 외, 2016; 이재웅 외, 2016). 상당수 선행연구는 은행 신용공여, 소상공인, 채무 불이행 예측 등 특정 사례에 한정되어 있거나, 전통 회귀분석법에 의존하고 있는 등 대안 신용평가를 위한 머신러닝 모형의 예측 성능을 분석한 연구는 현저히 부족한 실정이다(박주완 외, 2017; 송민찬과 류두진, 2021). 개별 기업 차원에서는 카카오뱅크·JT 저축은행 등이 고객을 대상으로 한 신용평가 모형을 마련하였지만 이는 개인 신용을 대상으로 한 빅데이터 기반의 신용평가 분석으로써 기업 신용등급 분석과는 다르다고 할 수 있다1. 근래 들어 일부 금융권을 중심으로 기업 부문 대안신용평가 모형을 마련하려는 움직임이 감지되고 있지만, 보다 다양한 기업을 대상으로 한 비재무정보 평가 모형 개발은 아직 개발이 더딘 것으로 평가된다2.
기존 재무지표 기반의 신용평가 모형의 가장 큰 한계는 다양한 사유로 발생하는 기업 부실을 설명하기 어렵다는 것이다. 이를테면 최근 들어 ESG, 탄소배출 등 비재무 성과가 중요해지며 MSCI 등 해외 신용평가사들이 비재무적 정보를 신용 평가에 반영하려고 하고 있다. 그러나 아직 국내 신용평가 모형은 재무지표를 중심으로 한 신용평가 등급을 부여하고 있다고 알려져 있으나, 회사채를 발행하는 기업에 대해 정보가 공개되고 있다. 이에 따라 실질적으로 비재무적 정보가 신용 위험에 반영되는지 파악하기 어려운 문제점이 있다.
본 연구에서 ‘비재무 정보’란 기업의 재무제표에 직접 반영되지는 않지만, 기업의 지속가능성과 위험 수준을 설명할 수 있는 비정량적 측면의 지표를 의미한다. 본 연구의 주요 관심 변수인 환경(E), 사회(S), 지배구조(G), 애널리스트 커버리지, 탄소배출량 등이 기업의 비재무적 특성을 반영한다고 할 수 있다.
이중 ESG 요소와 관련하여, 국내외 선행 연구는 대리인 이론(agency cost theory)에 기반하여 (개별) ESG 요소가 다양한 이해관계자 뿐 아니라 주주 가치 역시 개선시킨다는 점을 언급하고 있다. 구체적으로, 경영자가 사회적 책임 활동을 이행하는 과정에서 기업 투명성을 끌어올림으로써 주주와 이해관계자에게 신뢰를 제공함으로써 자본 비용 증대와 이에 따른 신용위험을 감소시킨다는 것이다(Jiraporn et al. 2014; Oikonomou et al., 2014; 박도준 외, 2023; 최동범과 정성준, 2022).
ESG 요소별로 살펴보면, 환경(E) 성과가 낮은 기업은 회사채 신용등급이 낮은 반면, 신용 스프레드는 높은 것으로 보고되고 있으며(Seltzer et al., 2022), 사회(S) 성과와 관련된 사회적 책임과 관련된 문제가 발생한 기업의 신용 스프레드 역시 높은 것으로 언급되고 있다(Goss et al., 2011). 다만, 두 요소 모두 단기적으로는 ESG 활동이 비용으로 인식되어 신용위험을 높일 수 있는데, 특히 한국 자본시장은 ESG 경영 도입이 초기인 만큼, 유해 물질이나 탄소배출량을 줄이는 ‘환경 성과’보다는 기업의 단기 수익성을 제고하는 탄소배출량 유발이 오히려 기업 가치에 증진시킨다는 국내 연구 결과도 있다(Lee & Cho, 2021). 연구 결과가 다소 혼재된 두 개별 ESG 요소와 대조적으로, 지배구조(G) 성과는 대리인 문제에 기반하여 기업의 투명성을 제고하고, 장기적으로 재무 건전성을 강화함으로써 기업 가치를 제고하는 동시에 신용위험을 낮출 수 있는 것으로 알려져 있다(최동범과 정성준, 2022).
또 애널리스트 커버리지는 외부 감시와 정보 효율성을 높여 자본시장에서의 신용할당 왜곡을 줄이는 역할을 한다. 특히 선행연구는 기업과 주주 사이에 존재하는 정보 비대칭을 줄임으로써 정보 효율성을 높이며 그 결과 기업의 자본 비용을 줄인다는 점을 보고하고 있다(Glosten and Milgrom, 1985; Healy and Palepu, 2001; 최금화와 정찬식, 2021).
본 연구는 비재무적 정보의 신용평가 활용 가능성을 분석하기 위해 두 가지 접근 방식을 취하였다. 실제 신용평가 방식이 신용평가사의 자산이라 외부에 알려질 수 없는 현실을 고려하여, 본 연구는 다양한 재무 지표 중심의 머신러닝 모형을 통해 신용평가사의 로직을 재현했으며, 머신러닝이 상장 폐지 여부를 잘 예측할 수 있는지 분석하였다. 특히, 랜덤포레스트와 그래디언트부스트트리(GBDT) 등 머신러닝 모형을 활용하여 기업의 투자등급(BBB)에 대한 확률예측값(부실변수)을 추정하였다. 모형 성과를 분석하기 위해 경영 위험에 따라 상장폐지가 발생하게 된 비자발적 상장폐지 기업에 대해 머신러닝 모형의 정확성을 재검증하였다. 둘째, 본 연구는 상장기업의 ESG 성과, 탄소배출량, 애널리스트 커버리지 등 다양한 비재무 정보를 이용하였으며, 이런 정보가 실제 기업의 부실 위험에 대하여 예측 능력을 갖추고 있는지 머신러닝에서 예측한 현재 신용평가사의 부실위험 수준을 통제하고 검증하였다. 본 연구는 비재무적 성과와 기업 부실의 관련성을 분석하기 위하여 Merton(1974)이 도입한 부도거리(Distance to Default)를 사용하였다. 이 부도거리는 기업의 위험을 파악하기 위해 규제 당국이나 연구자들이 널리 사용하는 척도로서3 부도거리가 클수록 기업의 건전성이 높은 것으로 판단할 수 있다. 본 연구는 이 부도거리를 종속변수로, 상장기업의 ESG 성과, 탄소배출량, 애널리스트 커버리지를 독립 변수로 고려하고, 앞서 머신러닝으로 예측한 부실변수와 여러 재무 변수를 조절 변수로 하여 패널 회귀 분석을 실시하였다. 재벌 여부, 부도거리의 크기 등 기준으로 추가적 분석을 수행하였다.
본 연구의 주요 분석 결과는 다음과 같다. 첫째, 재무제표 및 거시경제 변수 기반으로 신용 등급에 대한 머신러닝 분석을 수행한 결과, 전통적인 로지스틱 회귀 모형과 달리, 랜덤포레스트와 그래디언트부스팅 디시전트리(GBDT)는 기업 신용 상태가 건전한 기업뿐만 아니라 부실 기업에 대한 예측을 매우 정확도 높게 수행하였다. BBB 이하 신용 등급 기업에 대한 설명력이 떨어지는 로지스틱 회귀 모형과 달리, 랜덤포레스트 및 GBDT 는 BBB 이하 신용 등급 기업 및 BBB 이상 신용 등급 기업들에 대해 정확도가 각각 90%가 넘을 정도로 높은 성과를 나타냈다.
이와 같이 학습한 현재 국내 신용 평가사의 등급 산정 로직의 정확성을 판단하기 위해 비자발적 상장폐지 기업을 분석한 결과 역시, 표본
Table 1 The Composition of Firm Sample
| Firm number | Observation number | |
|---|---|---|
| All firms | 930 | 14,520 |
| Chaebols | 242 | 3,224 |
| Non-chaebols | 688 | 11,296 |
둘째, 본 연구는 앞서 머신러닝 모형으로 추정한 부실 변수를 기존 신용평가에 대한 대용 변수로 고려하여 가용 표본을 늘린 후 비재무 정보와 부도거리의 관계를 분석한 결과, 지배구조(G) 성과는 기업의 부도거리를 증가시켰으며, 이는 비재벌 기업에서도 명확하게 나타남을 확인하였다. 반면 환경 성과와 부도거리는 전체 표본에 대해서는 음(-)의 관계가 나타나고 있었다. 사회 성과는 전체 표본에서 통계적으로 음의 관계를 보이고 있으나 표본 선택 여부에 따라 결과가 크게 차이남을 제시하였다.
마지막으로, 애널리스트 커버리지 정보, 탄소배출량 등 대안 정보는 기업의 부도거리에 대한 설명력이 낮은 것을 확인하였다. 탄소배출량의 경우 매우 낮게 측정된 탄소배출권 가격에 따라 기업의 재무지표에 추가적 영향을 끼치지 않을 가능성이 있다. 애널리스트 커버리지는 애널리스트의 주요 분석 대상이 부실 가능성이 낮고 우량한 기업일 가능성이 높으며, 이에 따라 부도거리에 추가적인 설명력이 낮을 수 있다.
본 연구의 주요 공헌점은 다음과 같다. 첫째, 본 연구는 머신러닝 모형을 도입하여 기존의 재무 기반 신용 평가 모형을 보다 광범위하게 적용할 수 있는 방법론을 제시하였다. 특히 전통적인 로짓 모형에 비하여 머신러닝 기반의 모형은 신용평가사의 의사결정에 대하여 우수한 예측 성과를 보이는 것으로 나타났다. 이를 통해 등급 평가 대상의 수가 한정된 신용평가사의 결정을 시뮬레이션 하여 일반적인 기업 표본에 대해 확장할 수 있는 방법론을 제시하였다. 특히 기존 신용등급을 넘어서 다양한 표본에 대해 대안적인 분석을 해야 하는 향후 대안 신용 평가 모형에 있어서 활용도가 높을 것으로 판단된다.
둘째, 과거 논의가 부족한 비자발적 상장폐지 기업을 분석 대상으로 하여 기업 부실과의 관계 역시 확인하였다. 비자발적 상장 폐지는 투자자 입장에서는 기업의 부도에 준하는 이벤트로 고려될 수 있으나, 아직까지 연구가 활발하게 진행되지는 않았다. 본 연구는 채권 발행이 이미 어려워져 신용 등급이 없는 비자발적 상장 폐지 기업에 대해서 신용 등급 관련 연구 분야를 확장했다. 더욱이 본 연구의 결과는 이러한 비자발적 상장폐지기업들이 최종적으로는 재무적 지표에 기반한 기존 모형으로 잘 설명되고 있음을 밝혔는데, 비재무 정보는 이러한 최종적인 부실로 이끄는 재무적인 위험을 결정하는 조절 요소(moderating factor)로 볼 수 있음을 시사한다.
셋째, 본 연구는 ESG 정보가 추후 신용 등급 평가에 반영할 수 있는 주요한 정보가 될 수 있음을 확인하였다. 특히 지배구조(G) 관련 정보는 기업의 가치나 가치 변동성과 밀접하게 연관될 수 있고, 이에 따라 향후 기업의 부실위험을 예측하는데 설명력을 높일 수 있는 것으로 나타나고 있다. 이에 따라 지배구조 개선이 기업의 신용평가 향상에 미칠 수 있는 가능성을 확인했다. 반면 탄소배출량 정보, 애널리스트 커버리지 등 비재무 정보에 대해 향후 추가적인 분석이 필요할 수 있음을 시사한다. 특히 탄소배출권 가격 변화와 같은 외부 환경 변화, 증권사 보고서의 자연어 처리 분석 등 추가적인 분석이 필요하다.
본 연구의 구성은 다음과 같다. II 장에서는 선행 연구 및 문헌을 고찰하며, III 장에서는 연구 모형과 표본을 제시한다. IV 장에서는 머신러닝 분석 성과와 비자발적 상장 폐지 기업에 대한 분석을 수행하고 부도거리와 ESG, 탄소배출 성과, 애널리스트 커버리지와 관련성을 분석한다. V 장에서는 결론을 도출하여 대안 신용 평가 모형에 대한 시사점을 논의한다.
Ⅱ. 문헌연구
2.1 ESG 성과와 기업 신용위험
기업의 ESG 성과(점수)는 기업과 외부 이해관계자의 정보비대칭을 체계화된 점수 성과를 통해 해소한다는 것으로 알려져 있다. 즉, 기업이 대내외 이해관계자와 효율적인 계약을 이룰 수 있다는 점에서 기업의 지속가능성을 높여주는 동시에 기업 가치가 높아진다는 것이다. 자본시장에서 신용등급은 자본시장에서 기업과 다양한 이해관계자 사이에 존재하는 정보의 불균형을 해소하는 역할을 하는데, 사회적 책임 활동이 우수한 기업의 ESG 성과는 이해관계자와의 잠재적 갈등을 줄일 수 있으며, 이에 따라 정보 비대칭으로 인한 자본 비용을 감소시킬 수 있는 것이다. 이와 관련하여 선행연구는 대리인 이론에 기반하여, ESG 성과로 측정한 기업의 사회적 활동이 기업 평판과 경영 투명성을 개선하고, 경영자와 주주 간의 대리인 문제를 해소할 수 있다는 사실을 언급하고 있다 (Dhaliwal et al., 2011; Gelb and A. Strawser,2001). 결국 기업들이 적극적인 CSR 활동을 벌인다면 이해관계자와 갈등으로 발생할 각종 위험이 감소할 것이며, 이에 따라 투자자 입장에서는 이러한 기업에 대하여 상대적으로 신용위험이 낮은 것으로 간주할 수 있다.
국내 ESG 성과와 신용등급에 대한 연구 결과는 조금씩 혼재되어 있다. 임욱빈 외(2022)는 ESG 종합 등급 및 개별 등급이 높을수록 신용등급이 높은 것으로 분석하였다. 이는 신용평가기관이 이와 같은 비재무 정보 공개의 성과가 정보 비대칭을 낮추고 있는 것으로 판단함을 추측할 수 있는 결과이다. 김광민과 이현상(2021)은 비재무적 정보로서 ESG 가 회사채 신용등급 평가에 유의미한 양(+)의 관련성을 증명하였으며, 신용평가기관이 재무 자료뿐 아니라 ESG 등급을 신용평가 등급 산정에 반영하였다는 사실을 확인하였다. 또한 오상희(2021)는 신용평가 정보와 ESG 정보의 기업가치 관련성을 외국인 지분율을 통하여 검증하였다. 외국인지분율 더미 변수를 활용하여 ESG 변수와 기업가치의 관계를 분석한 결과 외국인 지분율이 고려되었을 때 기업 신용등급의 영향력이 크다는 사실을 밝혀냈다.
개별 성과로 봤을 때 ESG 성과는 기업의 특성에 따라 신용등급에 다른 영향을 끼치고 있다. 전진규(2021)는 국내 신용평가사가 제공하는 신용등급에 개별 ESG 요인이 어떻게 반영되는지 분석한 결과 ESG 요인은 기업의 신용평가에 유의한 양(+)의 영향을 미치는 것으로 나타났는데, 이는 국내 신용평가에 기업의 ESG 요인이 일부 반영된다는 것으로 분석되었다. 특히 지배구조(G) 요인이 기업의 신용 등급과 유의한 관계를 나타냈는데, 이는 기업 내 내부통제 장치, 윤리경영 등의 항목 덕분인 것으로 분석되었으며, 대조적으로 환경 및 사회 요인은 신용등급과 부분적으로 유의한 것으로 나타났다.
또 다른 선행연구는 기업의 ESG 성과는 신용평가사가 매기는 기업의 신용등급 향상으로 이어진다는 점을 언급하고 있다. 기업가치 측면에서 봤을 때 신용평가사의 신용등급은 채권 발행 기업의 지급능력을 의미하지만, 이런 지급 능력이 실은 기업의 미래 현금흐름을 내포하고 있다고 할 수 있다(김경옥과 하승화, 2017; 오상희(2021)). 뿐만 아니라 ESG 등급 부여가 기업의 재무 요인 뿐 아니라 사회적 책임과 시장 위험을 모두 고려하는 점을 감안하면, 기업의 ESG 성과는 기업의 신뢰도를 높이고 부도 확률은 낮출 것으로 추측해볼 수 있다.
위와 같은 연구 결과는 기업이 ESG 성과를 낼 경우 투자자와 시장 참여자로 하여금 대외 신뢰도와 신용도를 높일 수 있으며 이에 따른 신용위험을 낮출 수 있다는 사실을 보여준다. 다만 국내 연구에서는 개별 ESG 성과에 따른 신용위험에 대한 연구 결과가 다소 혼재되어 있다(박도준 외, 2023; 신태용 외, 2023). 먼저 신태용 외(2023)는 신용등급이 존재하는 국내 상장기업 270곳을 대상으로 ESG 점수, Merton(1974)이 제시한 부도거리(Distance to default)의 관계를 분석한 결과, ESG 성과와 기업의 신용위험의 관계를 입증하며, 특히 ESG 성과 가운데 지배구조는 부도거리에 대하여 강건하게 유의한 설명력을 나타낸다는 사실을 밝혔다. 이어 신태용 외는 환경 성과가 높을수록 오히려 신용위험을 높이는데, 이는 환경경영에 따른 성과가 오히려 비용으로 간주되어 신용위험을 끌어올린다는 측면에서 기대비용 이론과 부합한다고 분석하였다. 박도준 외(2023)는 ESG 개별 항목과 부도거리로 측정한 신용위험과 관계를 분석한 결과 지배구조(G)는 신용위험을 낮추는 것으로 나타났으며, 환경(E)은 신용등급과 신용위험에 모두 영향을 미치지 않는다는 점을 강조하였다. 박도준 외는 일부 신용평가사가 환경(E) 성과를 신용평가에 반영한다는 최근 추세를 언급하며, 추후 시장이 이런 분위기를 반영할 것이라고 기대하였다. 이러한 연구 결과는 ESG 경영이 초기 단계인 한국 자본시장에서는 환경(E) 성과보다는 단기적 수익을 강조 하는 탄소배출량이 국내 기업의 기업 가치, 혹은 신용 등급과 밀접한 관련성이 있음을 시사한다(Lee & Cho, 2021).
전진호(2018)가 경실련 경제정의연구소의 경제정의지수(KEJI)를 활용하여 2005년부터 2011년 사이 기업 샘플을 분석한 결과, 환경(E) 및 사회(S) 성과와 신용등급 간의 혼재된 결과가 나타남을 언급하였다. 구체적으로, CSR 항목 가운데 건전성과 기업의 사회적 책임 활동 총점이 높은 기업은 신용등급이 높게 나타났지만, 환경 보호 만족도와 기업 신용등급 간에는 반대되는 결과가 나타났다. 또한 사회적 책임 활동 중 공정성과 경제 발전 기여도가 높으며 대형 감사인이 감사하는 기업은 신용등급이 높게 나타났지만, 건전성이 높으며 대형 감사인이 감사하는 기업은 신용등급이 낮은 것으로 분석되었다.
반면 최동범과 정성준(2022)은 지배구조가 건전하지 않거나, 시장 감독에서 벗어난 기업은 환경(E)과 사회(S) 성과의 개선이 오히려 기업 가치를 훼손시킨다는 점을 강조하였다. 사후 평가가 쉽지 않은 경영 목표를 추구하는 것이 오히려 경영자 입장에서 자원의 사적 유용을 가능케 함으로써 대리인 문제를 악화시킨다는 것이다. 이는 기업 입장에서 바람직한 환경(E)과 사회(S) 성과를 추구하기 위해서는 미국 등 선진국과 같이 지배구조(G) 체계의 개선이 전제되어야 한다는 사실을 시사하고 있다.
결국 기업의 ESG 성과는 신용평가에 명시되진 않더라도 재무 및 사업 건전성 등 신용평가의 주요 요소에 차별적인 영향을 끼치는 것이라고 요약할 수 있다. 다만 ESG 성과 중에서도 지배구조 성과는 기업 가치 및 신용등급 개선과 일관적인 관련성이 보고되고 있는데, 이는 지배구조(G) 성과가 한국 자본시장 고유의 특성과 긴밀함을 내포하고 있다. 위와 같은 논의를 종합하여 정리한 첫 번째 가설은 아래와 같다.
가설 1: 기업의 ESG 성과는 부도거리와 양(+)의 관계를 가질 것이다.
가설 1-1: 기업의 E(환경) 성과는 부도거리와 음(-)의 관계를 가질 것이다.
가설 1-2: 기업의 S(사회) 성과는 부도거리와 음(-)의 관계를 가질 것이다.
가설 1-3: 기업의 G(지배구조) 성과는 부도거리와 양(+)의 관계를 가질 것이다.
2.2 애널리스트 정보와 기업 신용위험
증권사 애널리스트는 일종의 정보 중개자로서 기업과 투자자 등 다양한 이해관계자 간의 정보 비대칭성을 줄임으로써 자본시장에 유통되는 정보의 효율성을 높이는 기능을 한다(Healy and Palepu, 2001). 특히 애널리스트는 리포트 발간 등 외부 투자자에 정보를 제공하며 자본시장에 긍정적인 기여를 한다. 임병권과 박재환(2017)은 애널리스트가 다양한 기업 및 산업 정보를 대중에 제공함으로써 국내 자본시장에 긍정적인 영향을 미친다고 주장하였다. 정석우 외(2011)는 애널리스트는 전문적인 산업 지식을 공급함으로써 외부 투자자와 경영자의 의사 결정에 기여한다는 사실을 언급하였다. 요약하면, 애널리스트가 생산하는 리포트는 투자자 입장에서 접근 가능한 정보로써, 특정 기업에 관한 추천 정보, 즉 매수 의견과 목표주가, 즉 적정 주가 등에 대한 예측치를 제공함으로써 정보 효율을 극대화한다고 평가할 수 있다.
‘애널리스트의 정보 공급 활동 정도’를 나타내는 애널리스트 커버리지가 자본시장에 미치는 영향은 여러 형태로 나타날 수 있다. Lys and Sohn(1990)은 애널리스트 커버리지는 긍정적인 시장 반응과 관련성이 있다는 점을 언급하였고, Ayers and Freeman(2003)은 애널리스트 커버리지가 높은 기업은 주가에 미래 이익에 관한 정보가 상대적으로 많이 담겨 있다는 사실을 주장하였다. 국내 연구에선 이재홍과 오명전(2013)이 과잉투자 기업의 애널리스트 커버리지가 낮을 경우 신용등급에 대한 부정적 영향이 더 크다는 점을 증명함으로써 애널리스트의 정보 공급 활동과 정보위험 간의 관련성을 확인하였다. 반면 일부 선행 연구는 애널리스트 커버리지와 기업 가치의 관계에 있어서 순기능과 역기능을 언급하고 있다. Ellul and Panayides(2018)는 애널리스트 정보가 주식시장에서 유동성을 공급할 뿐 아니라, 기업가치의 기준을 설정하는 순기능이 있다는 사실을 제시하였다. Bradshaw et al. (2009)은 애널리스트의 기업 전망은 낙관적인 측면이 과도하여, 오히려 이것이 기업 가치를 왜곡시키는 측면이 있다는 점을 언급하였다.
또 다른 선행연구는 애널리스트 커버리지와 부도 확률의 관련성을 보다 직접적으로 언급하고 있다. Fiorillo et al.(2024)은 애널리스트 커버리지가 줄어든 기업에 대하여 분석한 결과 이듬해 기업의 부도 확률이 3.80% 높아지는 사실을 밝혔으며 이에 대한 원인으로 애널리스트 부족에 따른 정보 비대칭 증가, 높은 자금 조달 제약, 낮은 주식 유동성 등을 꼽았다. 반면 이승훈과 김수현(2022)은 국내 주식시장에서 애널리스트 커버리지는 연구개발(R&D) 활동을 촉진시키는 점을 언급하였다. 특히 이들은 2003~2012년 국내 애널리스트 커버리지 데이터와 국내 특허 데이터가 정리된 데이터를 분석하여 애널리스트 커버리지와 기업 특허 수 간의 유의미한 양(+)의 관계가 있다는 사실을 도출하였다.
위와 같은 논의를 종합하였을 때 애널리스트는 시장에 정보 공급 활동을 함으로써 기업에 대한 정보 위험을 줄이며, 이는 신용등급 혹은 신용위험으로 측정되는 기업의 신뢰도 향상으로 이어진다고 볼 수 있다. 구체적으로 애널리스트의 긍정, 혹은 부정 전망의 정도를 뜻하는 애널리스트 커버리지가 특정 기업에 낙관적이거나 부정적인 측면을 부각한다면 이는 시장 투자자의 투자 의사 결정에 영향을 끼치는 주요 요소로 작용할 수 있다. 위와 같은 논의를 종합하여 두 번째 가설은 아래와 같다.
가설 2: 기업의 애널리스트 커버리지는 부도거리와 양(+)의 관계를 가질 것이다.
2.3 탄소배출량 정보와 기업 신용위험
탄소배출량과 기업가치에 대한 해외 연구는 탄소배출량과 기업 가치 간 음(-)의 관계를 주목하고 있다(Chapple et al., 2013; Matsumura et al., 2014; Vance, 1975). Matsumura et al.(2014)은 미국의 S&P500 기업을 대상으로 탄소배출량과 기업가치의 관계를 분석한 결과 두 변수 사이 유의한 음(-)의 관계를 발견하였다. Chapple et al.(2013) 역시 탄소배출권을 공개 거래하는 호주 기업을 대상으로 가치평가모형을 통하여 분석한 결과, 탄소배출량과 기업 주가 사이에 유의한 음(-)의 관계를 확인하였다. Vance(1975)는 기업의 환경 성과와 기업 가치의 관계를 분석한 결과, 우수한 환경 성과 달성에 있어 기업 내부의 자원이 소요되며 그 결과 두 변수 사이에 음(-)의 관계가 발견된다고 주장하였다.
신용위험과 직접적이지 않지만 국내 연구 역시 탄소배출량과 기업 가치 사이에 나타나는 부정적인 관계를 언급하고 있다. 박정환과 노정희(2017)는 탄소배출량이 기후변화 위험을 반영하는 것으로 작용하여 기업가치 하락에 영향을 끼치는 것으로 분석하였다. 이들은 2011~2014년 사이 국내 기업이 탄소배출 정보공개프로젝트(CDP) 보고서에 공시한 탄소배출량 정보와 토빈의 큐(Tobin’s Q)로 측정한 기업가치를 실증 분석한 결과 두 변수 사이에 유의한 음(-)의 관련성이 있음을 증명하였다. 최종서와 노정희(2016)는 탄소배출량 정보의 가치 분석에 있어 자기선택 편의를 교정하여 검증한 결과 탄소배출량과 주가, 신용등급 사이의 관련성에 있어 음(-)의 상관관계를 검증 하였다. 이처럼 전반적으로 국내외 선행 연구는 탄소 배출 정보와 기업 가치의 음의 관계를 보고하고 있다는 사실을 알 수 있다.
일부 국내 연구는 국내 기업의 특성을 고려하여, 탄소배출량과 기업가치 간의 양(+)의 관계가 존재할 수 있다는 점을 언급하고 있다. Lee and Cho(2021)는 841개의 국내 기업을 514개의 재벌기업집단과 335개의 비재벌기업집단으로 구분하여, 국내 CDP 보고서에서 수집한 탄소 배출량과 기업별 재무 데이터를 분석하였다. 그 결과 재벌기업집단의 탄소 배출량과 기업 가치 사이에 양(+)의 관계가 있다는 사실을 밝혀냈다. 이는 투자자들이 탄소배출량이 기업가치에 부정적 영향을 끼친다는 선진국 위주의 선행 연구와 대조되는 결과이다. 안미강과 고대영(2017)은 2010년부터 2014년까지 CDP 보고서에서 탄소배출 정보가 공개된 기업을 대상으로 분석한 결과 탄소배출 공시 변수가 공적부채 변수와 금융부채 변수에 유의한 양(+)의 영향을 끼친다는 점을 보고하였다. 즉, 부정적인 정보로 간주될 수 있는 탄소배출 정보를 자발적으로 공개하는 것은 기업이 사회적 책임을 수행한다는 신호 효과이며, 기업의 정보 비대칭 측면에서 보다 우위를 가짐으로써 용이한 타인자본 조달을 가능케 한다는 것이다.
요약하면, 선행연구는 탄소배출량 정보가 기업 가치, 신용등급과는 음(-)의 관계를 가진다는(박정환 외, 2017; 최종서와 노정희, 2016) 사실을 언급하고 있다. 이런 측면에서 기업의 탄소배출량은 기업에 있어 기후변화에 따른 신용위험을 반영하는 ‘환경 부채’로서의 함의를 가지고 있으며, 시장 기준의 신용위험과는 양의 관계, 이를 역으로 추산하는 부도거리와는 음의 관계를 지닐 것으로 예측된다. 위와 같은 논의를 종합하여 세 번째 가설은 아래와 같이 정리할 수 있다.
가설 3: 기업의 탄소배출량은 부도거리와 음(-)의 관계를 가질 것이다.
위 세 가지 가설을 정리하면, 대부분의 선행연구는 신용등급이 존재하는 상장기업을 중심으로 ESG 와 탄소 정보의 신용위험 효과를 분석하였지만, 대부분 전통적 회귀모형에 의존하였다. 반면, 본 연구는 신용등급이 부여되지 않은 비자발적 상장폐지 기업을 포함함으로써 신용평가 범위를 확장하고, 머신러닝을 통해 신용평가사의 등급 산정 로직을 대체 변수로 구축했다는 점에서 차별적이라고 할 수 있다. 특히 관련 연구(박도준 외, 2023; 신태용 외, 2023)는 신용등급이 존재하는 상장기업에 한하여 분석하였으며, 이런 측면에서 본 연구는 신용등급이 존재하지 않는, ‘비자발적 상장폐지 기업’을 분석 대상에 포함하였다. 또한, ESG 성과, 탄소배출량, 애널리스트 정보와 부도거리로 측정한 신용위험의 관계를 분석함으로써 비재무 정보의 신용위험 예측력을 분석했다는 측면에서 실증 연구의 공헌도를 갖추고 있다고 할 수 있다.
Ⅲ. 표본과 연구 모형
3.1 표본과 데이터 구축
본 연구의 분석 표본은 2000년부터 2021년까지 KOSPI 상장 이력이 있는 기업을 분석하였으며 금융 기업은 제외하였다. 또한 기업의 특성에 따른 대안 신용평가 모형의 예측력을 검증하기 위하여 기업 샘플을 전체 기업에 더하여 강건성을 확인하기 위해 재벌기업집단, 비재벌기업집단으로 구분하여 추가적인 분석을 수행하였다. 그 결과 전체 기업의 기업 숫자는 930개, 관측치는 14,520개에 이르며, 재벌의 경우 242개, 3,224개, 비재벌기업집단의 경우 688개, 11,296개로 나뉜다. 본 연구에 쓰인 분석 표본의 기업 개수와 관측치는
본 연구는 탄소배출 정보(Matsumura et al.,2014; Lee and Cho, 2021; 최종서와 노정희, 2016), ESG 성과(Kim et al., 2014; Lee et al., 2021; 최금화와 강상구, 2021), 애널리스트 커버리지(Ayers and Freeman, 2003; Lys and Sohn, 1990; 이승훈과 김수현, 2022; 이재홍과 오명전, 2013) 등 다양한 선행연구에 언급된 문헌을 참고하여 다양한 재무·거시경제 변수를 산출하였다. 각 데이터의 출처는 기업 재무 데이터와 애널리스트 커버리지 정보의 경우 FN 가이드에서 운영하는 데이터가이드, 거시경제 변수는 한국은행 경제통계시스템 홈페이지에서 입수하였다. 법인세율, 알트만 Z-점수 등은 회계법인 홈페이지와 관련 문헌을 참고해 작성하였다. 이어 각 기업의 ESG 점수는 ESG 평가 기관인 서스틴베스트에서 입수한 통합 및 개별 ESG 평가 점수를 활용하였다. 한국 탄소정보공개프로젝트(CDP)의 연간 보고서에서 탄소배출량 정보는 직접 수집하며, 직접 탄소 배출량인 scope 1과 간접 탄소 배출량인 scope 2의 합계를 개별 기업의 탄소배출량으로 활용한다. 기업들은 매년 CDP 에 자발적으로 자사의 탄소배출 정보를 제공하여 공시하는데, 이처럼 CDP 를 통하여 외부에 공개되는 기업의 탄소배출량은 신뢰성이 높은 것으로 평가되며, 기업이 CDP 를 통해 탄소배출 정보를 공시하는 것은 자발적인 선택이지만 CDP 의 탄소배출 요청에 우선 응하는 것은 추후 기업이 같은 선택을 내릴 경향이 높은 것으로 알려져 있다(Matsumura et al., 2014; 최종서와 노정희, 2016). 본 연구는 재벌기업집단과 비재벌기업집단으로 구분하여 추가 분석을 수행하였다. 재벌기업집단 소속 기업 선정은 공정거래위원회가 매년 지정하는 상호출자제한기업집단 리스트를 참고하였다. 각 비재무 정보 데이터의 기간은 탄소배출량은 2013~2017년, ESG 점수는 2010~2020년, 애널리스트 커버리지는 2000~2021년이다.
본 연구는 신규 상장 기업 혹은 과거 상장폐지 기업이 누락됨에 따라 발생하는 생존 편의(Survivorship bias) 문제를 해소하기 위하여, 분석 기간 내 신규 상장기업과 상장폐지 기업을 기업 표본에 모두 포함시켰다. 또한 각 종속 변수와 설명 변수의 극단 값은 1% 수준으로 윈져라이즈(Winsorize)하였다. 이어 본 연구는 머신러닝 및 실증 모형을 분석하기 위해, Amini et al.(2021)을 참고하여 시장가치총부채비율(TDM), 총자산대비 영업이익(Profit), 총자산 변화율(Assets), 기업 장기존속 여부(Mature), 시장가-장부가 비율(Mktbk), 총자산 증감률(Chg Asset), 자본지출(Capex), 유형자산(Tang), 연구개발비(RD), 특수산업(Unique), 판관비(SGA), 현금성자산(Cash), 법인세율(Taxrate), 감가상각비(Depr), 주가변동성(Stock Var), 알트만 Z-점수(Zscore), 신용등급(Rating), 개별 주가수익률(Stock), 시장 주가수익률(Crspret), 부채비율 중앙값(indstlev), 총자산 증감률 중앙값(industgr)을 활용하였다. 또한 자산 더미 변수(Size), 기업 더미(Growth), 첨단기술 더미(Hightech) 역시 활용하여 머신러닝 분석에 이용하였다. 한편 머신러닝 모형을 통해 예측한 낮은 신용등급에 대한 확률값 역시 부도거리 실증 모형의 조절변수로 사용하였다. 한편 머신러닝 모형을 분석하기 위해 활용한 거시경제 변수로는 10년과 1년물 국채스프레드 수익률 차이(termsprd), 예상물가상승률(inflation), 당기순이익 증감율(Macroporf), 실질 GDP 성장률(Macrogr), 순배당율(Netpay) 등을 도입하였다. 구체적인 변수별 정의는
Table 2 Financial and Macroeconomic Variables
| Variable | Calculation Method |
|---|---|
| **Dependent Variable** | |
| DD | ※ 수식 1 참조 |
| Non-voluntarily delisted | 1 if non-voluntarily delisted, otherwise 0 |
| **Independent Variable** | |
| CO2 | Carbon Emission / Revenue |
| E/S/G/ESG | E/S/G/ESG Score |
| Analyst Coverage | Analyst recommendation score (based on reports over the previous six months) Strong Buy=5, Buy=4, Neutral, 3, under Weight=2, Sell=1 |
| **Financial Variables** | |
| Rating | Firm’s credit rating dummy (1 = BB or higher, 0 = below BB) |
| TDM | (Current liabilities + Long-term liabilities) / Market capitalization |
| Profit | (Operating income before depreciation) / Total assets |
| Assets | Logarithm of total assets |
| Mature | 1 if firm data has existed for 5 years or more, 0 otherwise |
| Mktbk | Market capitalization / Total assets |
| Chg Asset | Annual growth rate of total assets |
| Capex | Capital expenditures / Total assets |
| Tang | Tangible assets / Total assets |
| RD | R&D expenses / Revenue |
| Unique | 1 if the firm operates in aerospace, missile, aviation, computer, semiconductor, or chemical-related industries; 0 otherwise |
| SGA | Selling, general, and administrative expenses / Revenue |
| Cash | Cash and short-term investments |
| Taxrate | Statutory corporate tax rate |
| Depr. | Depreciation expenses / Revenue |
| Stock Var | Annualized volatility of daily stock returns |
| Zscore | Altman’s Z-score^4 |
| Stock | Annual cumulative stock return |
| Crsp Ret | Annual cumulative return of the stock market |
| Industlev | Median value of TDM |
| industgr | Median value of Chg Asset |
| **Macroeconomic Variables** | |
| Termsprd | Yield spread between 10-year and 1-year government bonds |
| inflation | Expected inflation rate |
| Macroporf | Logarithm of annual net income of non-manufacturing firms |
| Macrogr | Real GDP growth rate |
| Netpay | (Cash dividends + Net increase in common and preferred stock) / Total assets |
| **Other variables** | |
| Size | Assigned 2 if the firm’s total assets are in the top 30%, 1 if in the middle 40%, and 0 if in the bottom 30% |
| Growth | Assigned 2 if the firm is in the top 30%, 1 if in the middle 40%, and 0 if in the bottom 30% |
| High-Tech | 1 if the firm operates in IT products or services, 0 otherwise |
3.2 비자발적 상장폐지 기업 및 부도 거리
본 연구는 기업의 비자발적 상장폐지 여부, 부도 거리(Distance to Default)를 종속변수로 선정하였다. 상장 폐지는 정리매매 혹은 최종 파산으로 이어져 투자자들에게 가장 큰 손실을 끼칠 수 있는 이벤트로 정의할 수 있다. 본 연구는 기업 공시 채널인 KIND 를 이용하여, 인수합병과 같이 자발적인 상장 폐지 신청 기업을 분석 대상 기업에서 제외하는 방식으로 비자발적 상장 폐지 여부를 정의하였다. 비자발적 상장 폐지 기업의 대다수는 기업의 부실(자본잠식, 감사의견 거절 등)과 관련성이 높은 것으로 확인된다.
본 연구의 연구 기간(2000-2021년) 동안 유가증권 시장 기준으로 비자발적 상장폐지 기업으로 분류된 기업 수는 총 189개이다. 해당 기업들의 연구 기간 내 비자발적인 이유로 상장 폐지되었으며, 분석에 있어 상장폐지와 가장 가까운 회계연도를 기준으로 분석하였다.
본 연구는 비자발적 상장폐지 기업으로 분류된 기업에 대해 기존의 국내 신용평가사 모형이 잘 예측하는지 판단하기 위해 기업의 상장폐지 시점에 대해 가장 최근접 회계연도를 기준으로 하여 분석하였다. 이는 상장폐지가 된 후 공시의무가 없어져 회계 정보를 활용할 수 없는 상황에 기인한다. 또한 본 연구는 신용위험 측정을 위하여 Merton(1974)이 소개한 부도거리(Distance to default)를 계산하였다. 부도거리는 시장에서 거래되는 주식가격과 수익률의 변동성에 기반하여 신용위험 측정한 값을 말한다. 구체적으로 총자산의 시장가치와 부채의 차이를 총자산의 변동성으로 나누어 산출한 값이다. Merton(1974)은 채권 만기 도래 시 주주가 채권을 상환하고 남은 자산을 소유하기 때문에, 자본은 콜옵션과 같은 성격을 갖고 있다고 밝힌다. 부도거리는 시장에서 거래되는 주식가격과 수익률의 변동성에 기반하여 신용위험을 측정한 값을 말한다. 이는 총자산의 시장가치와 부채의 차이를 총자산의 변동성으로 나누어 산출한 값인데, 만기시점에서 자산의 기대가치가 부도점에서 얼마나 떨어져 있는지 여부를 표준편차의 배수로 나타낸 값이라고 할 수 있다. 부도거리 값(DD)은 기업의 부도 가능성을 부도 확률로부터 역산한 거리를 나타낸 것으로서 그 값이 크면 부도 가능성이 낮은 기업이며, 그 값이 높은 부도 가능성이 낮은 기업이라고 할 수 있다. 구체적인 식은 아래 수식 1과 같다.
위 식에서 총자산의 시장가치($V$)는 각 기업의 연도별 시가총액(E)과 부채의 만기상환액(L)을 합산하였다. 기업의 레버리지 비율이 작을수록(L/V), 그리고 기업가치의 변동성이 작을수록 기업의 부도거리가 증가한다. 부채의 만기상환액($L$)은 Vassalou and Xing(2004), Bharath and Shumway(2008)의 방법을 참고하여, 유동부채 전체와 비유동부채의 50%를 합산하였다. 무위험이자율은 1년 만기(364일) 통안증권 금리를 사용하였다. 기업의 시장가치의 변동성($\sigma_v$)은 개별 기업 주식의 52주 주간 변동성을 기준으로 측정하였다. 1년 동안 부도가 일어날 수 있는 지표를 고려하여 (T-t)는 1년으로 고정하였다.
3.3 머신러닝 모형
본 연구는 기업의 부실 위험에 대한 분석에 앞서, 머신러닝 모형을 활용하여 현재 신용평가사가 활용하는 신용 등급 산출 로직을 재구성해보고자 한다. 이를 위해 기업의 투자적격등급(BBB) 이상과 이하에 대한 기업을 구분하여 투자적격등급 아래의 경우는 1을, 투자적격등급 이상의 기업의 경우에는 0을 부여하는 지시 변수를 바탕으로 머신러닝 모형을 분석하였다.
모형 분석을 수행하기 위하여 본 연구는 2000~2021년 사이 국내 상장기업을 대상을 분석하였으며, 이진 분류(Binary Classification)에 성과가 높은 랜덤 포레스트, 그래디언트부스팅트리(GBDT)와 같은 머신러닝 알고리즘을 사용하여 예측 성과를 비교 분석하였다. 추가적으로 모형의 적합도를 기존 방식들과 분석하기 위하여 로지스틱 회귀 모형을 비교군으로 사용하였다. 머신러닝 분석을 위한 train set 은 2000년부터 2015년까지, test set 은 2016년부터 2021년도까지로 구분하여 반영하였다.
본 논문에서 머신러닝 모형 중 랜덤포레스트는 새로운 데이터를 다양한 결정 트리에 입력시키며, 각 결정 트리가 분류한 결과에서 가장 많이 득표된 결과(hard voting)가 최종적인 분류 결과로 선정된다(Altman and Krzywinski, 2017; Breiman, 1996; Breiman, 2001). 랜덤포레스트 모형의 장점은 일부 결정 트리에서 발생할 수 있는 과적합 문제를 예방할 수 있다는 것이다. 본 연구는 랜덤포레스트 모형 구축을 위해 N 규모의 샘플을 train data(표본 내 데이터)에서 추출한 뒤 부트스트랩을 진행하였다. 이후 본 연구는 종속 변수의 라벨이 카테고리형{0,1}이란 점을 고려하여 다수결의 원칙에 따라 가장 많이 예측된 클래스값을 최종값으로 하였다. 그 결과는 수식 $\hat{C}_{rf}^B(x) = majority\ vote\ \{\hat{C}_b(x)\}_1^B$과 같다.
또한 본 논문은 그래디언트부스팅디시전트리(GBDT)를 도입하였다. GBDT 의 기반이 되는 그래디언트부스팅머신(GBM)은 회귀, 분류 모델에 모두 활용 가능하다. 또한 랜덤포레스트와 같이 여러 결정 트리를 묶어 강력한 예측 모델을 만드는 앙상블 머신러닝 모형으로 꼽히며, 랜덤포레스트 모형과 유사점이 있다. 랜덤포레스트와 차이점은 현 트리가 이전 트리의 예측값과 타깃값 사이의 오차를 줄이는 방향으로 형성되는 알고리즘이라는 것이다. 이를 위해 GBDT 는 경사하강법(gradient descent)을 사용해 추가되는 새로운 트리의 예측 값을 보정한다.
머신러닝 분석의 정확성을 높이기 위해 본 연구는 그리드 서치(grid search)를 통하여 다양한 하이퍼파라미터 튜닝(hyperparameter tuning)을 수행하였다. 특히 머신러닝 분석에 쓰이는 데이터가 불균형한 점을 감안하여 성능 평가 점수로 활용한 f-1 score 와 가중치($w$)를 제외한 모수에 대하여 그리드서치를 수행하였다. class 별 가중치는 0의 경우 0.6353, 1의 경우 2.3466이다. 본 연구가 King and Zeng (2001)을 참고하여 해당 가중치 값을 도출한 수식은 아래와 같다.
위 수식에서 $w_0$은 투자적격등급 이상 기업(class 0)에 대한 가중치, $w_1$은 투자적격등급 이하 기업(class 1)에 대한 가중치를 뜻한다. 또 각 식에서 $\tau$은 모집단의 비율에 대한 사전 정보를 기반으로 한 추정치를 뜻하며, $\bar{y}$은 각 샘플에서 관찰된 비율(샘플링 확률)을 의미한다.
이러한 과정을 거쳐 머신러닝 모형이 학습되면 신용평가사가 예측하는 기업의 부실화 정도를 나타내는 부실 확률 예측값(Predictive value)을 구할 수 있다. 만약 머신러닝 모형의 추정 성과가 우수하면 이러한 확률값은 현재 기업의 부실화 정도를 신용평가사에서 판단하는 연속적인 변수로 고려될 수 있다. 특히 신용평가사의 신용 등급 정보가 채권을 발행하는 기업들 위주로 간행이 연속적으로 되지 않는 현실을 감안할 때, 예측 확률 값을 조절 변수로 사용하는 등 대안신용모형에서 다양한 변수를 넓은 표본에 한해 고려할 수 있다. 본 연구는 변수 중요도와 머신러닝 예측 성능까지 모두 분석한다.
3.4 부도거리 분석 모형
탄소배출량, ESG 성과, 애널리스트 커버리지 정보 등이 신용 등급 이외에 기업의 부실에 추가적으로 미치는 영향을 분석하기 위해 패널 회귀 분석 모형을 이용하였다. 종속변수로는 부도거리로 설정하였다. ESG 성과와 부도거리의 관계를 나타내는 실증 모형은 다음과 같이 표현된다.
여기서 DD 는 t 년도 회계연도를 기준으로 1년 뒤인 t+1년도의 부도거리를 나타낸다. 환경(E), 사회(S), 지배구조(G) 점수에 대한 분석을 기본으로 삼았으며, 전체 3부문을 다 포함하거나 ESG 총점만 독립변수로 구성한 실증 모형 분석 역시 수행하였다. 개별 기업들의 부도거리 특성을 반영하기 위해서 기업 고정효과 및 시간 고정 효과 역시 회귀모형 분석에 추가하였다.
본 모형에서 조절변수로는 머신러닝 모형에서 예측한 신용등급 확률값을 사용하였다. 추가로 로그화된 총자산, 장부 레버리지 비율, 산업 레버리지 비율, 고정 자산 비율, 영업이익률(ROA), 기업의 부실을 표현하는 Altman 의 Z 점수 역시 포함하였다. 산업 더미 변수 대신 산업 평균 레버리지 비율을 통해 산업간 차이가 가져올 수 있는 부도거리의 변동(Variation)을 보다 명확히 설명하였다.
탄소배출량과 부도거리의 관계는 ESG 정보와 유사하게 다음과 같이 모형화 하였다. ESG 정보 대신 탄소배출 정보를 독립변수로 추가하였으며, 관련 기업 변수와 고정효과를 모형에 추가하였다.
끝으로 본 연구는 애널리스트 커버리지와 부도거리의 관계를 다음과 같이 설정하고자 한다. 표본이 부족한 탄소데이터와 달리 애널리스트 커버리지에 대해서는 E, S, G 를 조절한 모형과 조절하지 않은 모형 두 가지에 대해서 모형을 예측하였다. 이는 애널리스트 커버리지가 기업의 ESG 경영활동 관련 추가적인 정보를 전달하여 분석될 가능성을 고려한 것이다.
Ⅳ. 연구 결과
4.1 머신러닝 모형의 예측 성과
본 연구는 전통적인 로지스틱 모형과 기계학습 알고리즘인 랜덤 포레스트, GBDT 를 통하여 기업의 투자 등급(BBB)에 대한 예측 성능을 분석하였다.8 또한, 본 연구는 이진 분류에서 성능 지표로 잘 활용되는 Confusion matrix 분석을 수행하였다. 이는 학습된 분류 기반 머신러닝 모델이 예측 시 얼마나 confusion(혼란)한지 나타내며, 모형의 정확도(Accuracy)를 알려주는 지표이다. 정확도는 실제와 예측 데이터를 비교 시 두 데이터가 얼마나 동일한지, 클래스 불균형(class imbalance)을 판단할 수 있다. 머신러닝 및 로지스틱 모형의 정확도를 알려주는 수식은 다음과 같다.
위 수식에서 TP, TN, FP, FN 은 각각 True Positive, True Negative, False Positive, False Negative 를 뜻한다. 즉, 투자적격 등급(BBB) 이하 등급은 1, 그렇지 않은 채권 등급이 0일 때, True 는 0을, Negative 는 1을 정확하게 예측한 값을 의미한다. 즉, 정확하게 예측한 두 값(TP, TN)의 합을 전체 예측 값으로 나눈 값을 정확도라고 부르는 것이다.
본 연구는 로지스틱 모형과 랜덤포레스트 모형의 confusion matrix 를 train set 과 test set 를 대상으로 구현하였다. 이에 대한 결과는 다음 〈Figure 1〉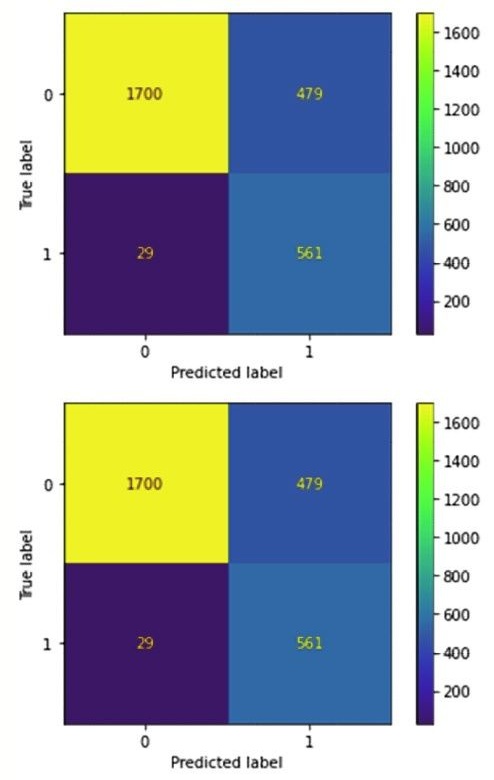
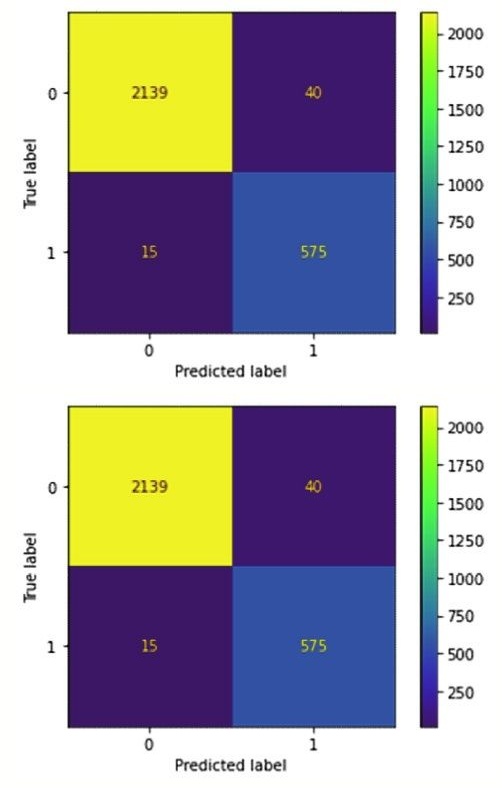
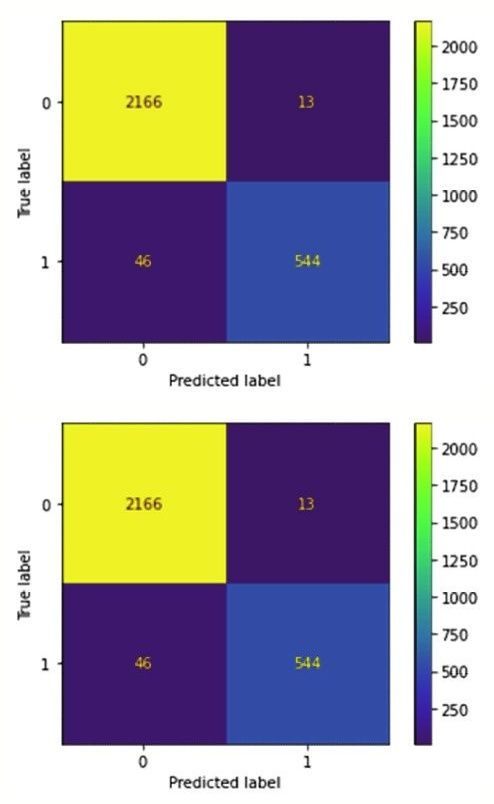
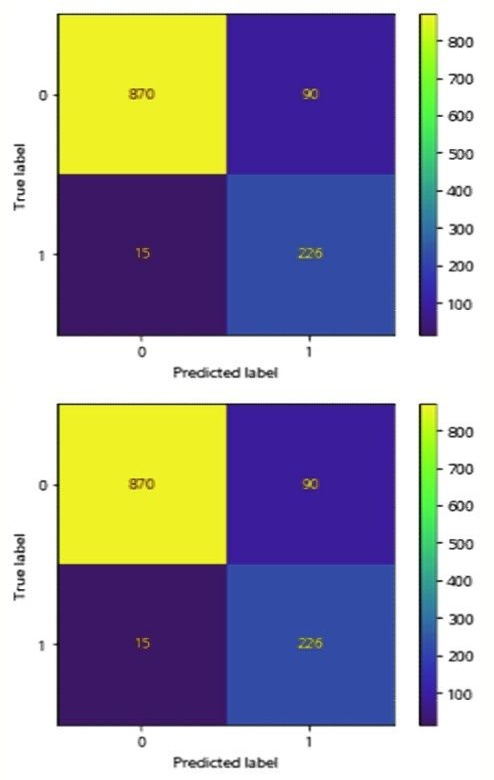
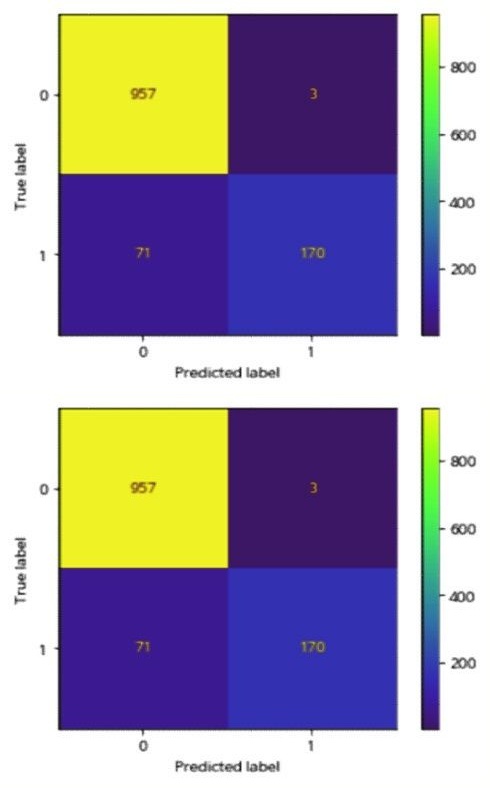
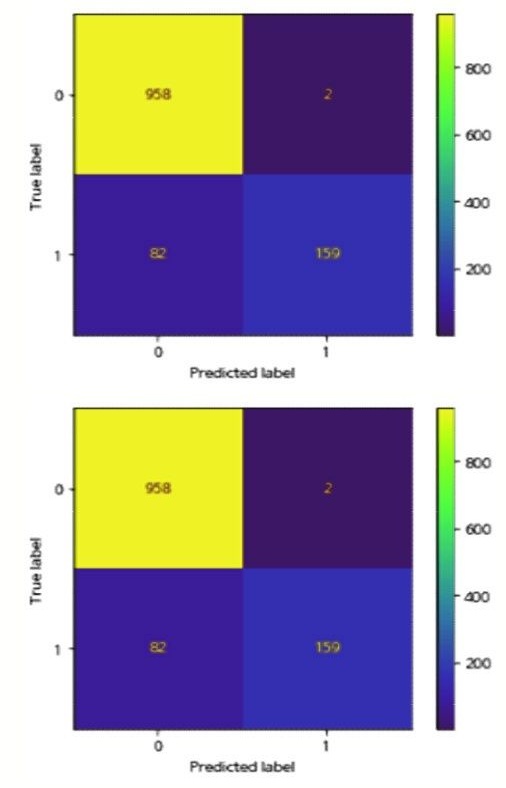
먼저 Train set 의 경우 〈Figure 1〉의 로지스틱 모형의 경우 True Positive 와 True Negative 의 합의 비율은 $81.7\% ((1750+561)/2769)$로 나타났으며, 이는 〈Figure 2〉의 랜덤포레스트의 $98.0\% ((2139+575)/2769)$, 〈Figure 3〉의 GBDT 의 $97.9\% ((2166+544)/2769)$보다 낮았다. 결국 confusion matrix 를 통한 정확도 예측은 머신러닝의 랜덤포레스트가 가장 성능이 뛰어나다고 평가할 수 있다. 이어 Test set 의 경우 〈Figure 4〉의 로지스틱 모형의 경우 True 와 True 의 합은 $91.3\% ((870+226)/1201)$로 나타났으며, 이는 〈Figure 5〉의 랜덤포레스트의 $93.01\% ((957+170)/1201)$, 〈Figure 6〉의 GBDT 의 $92.8\% ((958+159)/1201)$보다 낮았다. Train set 과 유사하게 confusion matrix 를 통한 정확도 예측 역시 머신러닝의 랜덤포레스트가 가장 성능이 뛰어난 것으로 나타났다.
이어, 본 연구는 로지스틱 모형과 랜덤 포레스트, GBDT 를 활용한 기업의 투자 등급(BBB) 예측 성능을 train set 와 test set 에 대하여 분석하였다. 먼저 train set 을 대상으로 분석한 결과는 〈Table 3〉
Table 3 Predictive performance for credit ratings - logistic regression model (train set)
| index | precision | recall | f1-score | support |
|---|---|---|---|---|
| 0 | 0.98323 | 0.78017 | 0.87001 | 2179 |
| 1 | 0.53942 | 0.95085 | 0.68834 | 590 |
| accuracy | - | - | 0.81654 | 2769 |
| macro avg | 0.76133 | 0.86551 | 0.77918 | 2769 |
| weighted avg | 0.88866 | 0.81654 | 0.83130 | 2769 |
Table 4 Predictive performance for credit ratings - random forest (train set)
| index | precision | recall | f1-score | support |
|---|---|---|---|---|
| 0 | 0.99304 | 0.98164 | 0.98731 | 2179 |
| 1 | 0.93496 | 0.97458 | 0.95436 | 590 |
| accuracy | - | - | 0.98014 | 2769 |
| macro avg | 0.96400 | 0.97811 | 0.97083 | 2769 |
| weighted avg | 0.98066 | 0.98014 | 0.98029 | 2769 |
Table 5 Predictive performance for credit ratings - GBDT (train set)
| index | precision | recall | f1-score | support |
|---|---|---|---|---|
| 0 | 0.97920 | 0.99403 | 0.98656 | 2179 |
| 1 | 0.97666 | 0.92203 | 0.94856 | 590 |
| accuracy | - | - | 0.97869 | 2769 |
| macro avg | 0.97793 | 0.95803 | 0.96756 | 2769 |
| weighted avg | 0.97866 | 0.97869 | 0.97847 | 2769 |
각 표를 살펴보면 투자적격 등급과 투자적격 이하 등급을 예측하는데 있어 차별적인 효과가 발생하고 있다는 점을 알 수 있다. 먼저 〈Table 3〉의 로지스틱 모형의 경우 투자 적격에 대해서는 98.32% 가량의 예측 성과를 보이지만 투자 비적격 등급에 대해서는 53.94%로 성능이 크게 감소한다. 반면 〈Table 4〉의 랜덤포레스트와 〈Table 5〉의 GBDT 모형의 정확도(precision) 예측 성능은 각 99.30%, 97.92%로 성과도 높을 뿐만 아니라 투자 적격 등급 및 투자 부적격 등급 예측에 있어서 큰 차이를 보이고 있지 않다.
이어 본 연구가 test set 을 대상으로 분석한 결과, 로지스틱 모형의 경우 예측 성과는 투자적격 등급과 투자적격 이하 등급에 있어 차별적인 효과가 발생하고 있다. 〈Table 6〉
Table 6 Predictive performance for credit ratings - logistic regression model (test set)
| precision | Recall | f1-score | support | ||
|---|---|---|---|---|---|
| 0 | 0.98305 | 0.90625 | 0.94309 | 960 | |
| 1 | 0.71519 | 0.93776 | 0.81149 | 241 | |
| accuracy | - | - | 0.91257 | 1201 | |
| macro avg | 0.84912 | 0.922 | 0.87729 | 1201 | |
| weighted avg | 0.9293 | 0.91257 | 0.91668 | 1201 | 〈Table 7〉 Predictive performance for credit ratings - random forest (test set) |
Table 7 Predictive performance for credit ratings - random forest (test set)
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 0 | 0.92278 | 0.99583 | 0.95792 | 960 |
| 1 | 0.97576 | 0.66805 | 0.7931 | 241 |
| Accuracy | - | - | 0.93006 | 1201 |
| macro avg | 0.94927 | 0.83194 | 0.87551 | 1201 |
| weighted avg | 0.93341 | 0.93006 | 0.92484 | 1201 |
Table 8 Predictive performance for credit ratings - GBDT (test set)
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 0 | 0.91939 | 0.99792 | 0.95704 | 960 |
| 1 | 0.98742 | 0.65145 | 0.785 | 241 |
| accuracy | - | - | 0.92839 | 1201 |
| macro avg | 0.9534 | 0.82468 | 0.87102 | 1201 |
| weighted avg | 0.93304 | 0.92839 | 0.92252 | 1201 |
이러한 성격은 비선형 결합을 통해 예측을 하는 머신러닝 모형들의 특성이 반영된 것으로 보인다. 즉, 일반적인 선형 결합에 로지스틱 함수를 적용하는 로지스틱 모형과 달리, 머신러닝 모형들은 하이퍼 파라미터 값에 따라 다양한 비선형 변환을 할 수 있으며, 결과적으로 ‘등급’이라는 이산화된 결과값을 설명하는데 있어서 유용한 결과를 얻을 수 있다. 뿐만 아니라, 이와 같은 예측 성과는 머신러닝을 통해 학습한 모형이 현재 신용평가사의 등급 예측을 매우 유사하게 복원할 수 있음을 시사한다. 한편 이후 분석에는 모형의 예측 성과가 우수한 랜덤 포레스트 모형을 중심으로 결과를 제시하고자 한다.
4.2 비자발적 상장 기업 분석
본 연구는 머신러닝 모형이 기업의 비자발적 상장폐지 여부를 잘 설명하는지 분석하여 test set 에서의 성과 분석을 넘어, 측도의 정확성을 추가적으로 검증하고자 한다. 이는 채권 신용등급을 가진 소규모의 데이터에서의 검증 한계를 보완하는 것으로써, 신용등급이 없더라도 실제 부실위험이 발생한 기업에 대해서 머신러닝으로 구축된 부실 측도가 잘 적용되고 있는지 검증한다고 할 수 있다. 비자발적인 상장폐지 기업을 대상으로, 비자발적 상장폐지가 확인된 날짜로부터 최근 회계연도를 기준으로 머신러닝 모형을 적용하여 기존 신용평가사 관점에서 분석하는 부실 정도를 측정했다.
비자발적 상장 폐지는 기업 경영에 있어서 부실 상황을 나타내는 매우 극단적인 이벤트다. 재무 성과가 부실하여 자본잠식이 우려됨에 따라 외부 감사인들이 의견을 거절하는 것이 대표적 사례다.
Table 9 Descriptive statistics of predicted default probability
| Statistic | All sample | Involuntary delisted |
|---|---|---|
| Minimum value | 0.000 | 0.384 |
| 1st quartile | 0.029 | 0.777 |
| Median value | 0.202 | 0.949 |
| 3rd quartile | 0.706 | 0.984 |
| Maximum value | 0.999 | 0.999 |
| Mean value | 0.355 | 0.880 |
| Standard deviation | 0.355 | 0.1326 |
일반적으로 기업의 부실은 부정적인 재무 성과의 점진적 누적으로 이루어지는 경우가 대다수다. 이에 따라 상장폐지 이전부터 상장폐지까지 점차적으로 기업의 부실화가 심해지는 것이 보다 일반적인 상황이라고 볼 수 있다. 본 연구는 상장폐지 이전부터 상장폐지까지 비자발적 상장 폐지 기업의 부실 확률이 증가하는지 확인하였다. 구체적으로, 상장폐지와 근접한 회계연도를 기준으로 이전 4년 간 부실 확률 변화를 측정한 결과, 현재 신용평가 모형은 상장 폐지 기업의 부실화 정도를 시계열 관점에서 역시 잘 나타내고 있다. 즉 4년 전의 평균 부실확률이 이미 77.4%이며 1년도 전에서는 85.3% 수준으로 예측하여, 평균값이 점증적으로 증가하고 있는 양상을 보이고 있다. 다시 말해, 머신러닝 모형으로 재현한 기존의 신용평가 모형이 비자발적 상장 폐지 기업의 부실을 잘 예측하고 있음을 확인하여 본 머신러닝 모형 성과의 우수성과 정확성을 다시 한번 확인한다. 이는
Table 10 Changes in the default probability of involuntarily delisted firms
| Period (Yearly) | t-4 | t-3 | t-2 | t-1 | t=0 | |
|---|---|---|---|---|---|---|
| Average default probability | 0.774 | 0.787 | 0.829 | 0.853 | 0.880 |
4.3 대안신용 정보와 부도거리 분석
4.3.1 ESG 정보 분석
본 절에서는 부도거리와 ESG 정보, 애널리스트 커버리지, 탄소배출 정보와의 관계를 분석하여, 비재무적 변수의 신용위험 영향력을 확인하고자 한다.
본 연구는 기업 및 시간 고정효과까지 고려한 패널 회귀 모형을 통해 부도거리와 ESG 정보의 관계를 분석하였다. 총자산(Total asset), 레버리지(Leverage), 산업 레버리지(Ind. leverage), ROA, Tobin’s Q, 고정자산비율(Fixed asset ratio), 파산 확률(Z score) 등 기업 변수 이외에도, 앞서 머신러닝을 통하여 추정한 부실 확률은 ‘부실 변수(Default)’로 추가하여 기존 신용등급에 대한 영향력을 포괄적으로 고려하였다.13,14 앞서 언급하였듯이, 부실 변수는 현재 신용평가사가 재무 정보를 기반으로 판단하는 부실화 정도를 나타내며, 기존 신용평가의 대리 변수로 쓰일 수 있다. 즉, 부실 변수를 통제할 경우 ESG 성과, 애널리스트 커버리지, 탄소배출량 등 비재무 정보의 순수 효과를 분리할 수 있는 것이다. 즉, 비재무 정보가 신용위험에 직접적 영향을 미치기보다는, 재무위험을 매개하는 보조 요인으로 작동함을 보여준다. 이는 비재무 정보는 신용위험의 직접 원인이 아니라, 부실 리스크를 결정하는 재무변수의 조절 요인이라는 선행연구를 뒷받침한다고 할 수 있다 (Oikonomou et al., 2014).
본 연구는 회귀분석에 앞서, 변수 간 기초통계량과 상관분석을 제시하고자 한다. 먼저,
Table 11 Summary Statistics
| Variable | Average | Median | Standard Deviation | Minimum | Maximum |
|---|---|---|---|---|---|
| DD | 2.97 | 2.046 | 3.2 | -0.407 | 19.07 |
| ESG | 34.896 | 35.645 | 31.773 | 0.0 | 99.925 |
| E | 13.38 | 3.6 | 19.545 | 0.0 | 96.415 |
| S | 21.214 | 20.205 | 20.559 | 0.0 | 88.19 |
| G | 32.88 | 46.13 | 25.883 | 0.0 | 81.28 |
| ROA | 1.077 | 0.906 | 0.805 | 0.394 | 27.208 |
| Tobin’s Q | 0.069 | 0.068 | 0.079 | -0.217 | 0.886 |
| Total asset | 0.131 | 0.044 | 0.523 | -0.483 | 34.362 |
| Fixed asset(%) | 0.877 | 0.333 | 3.085 | 0.003 | 136.532 |
| Leverage | 0.51 | 0.498 | 0.414 | 0.086 | 26.477 |
| Z score | 5.323 | 6.102 | 8.178 | -31.516 | 227.539 |
| Ind. leverage | 0.549 | 0.532 | 0.097 | 0.429 | 0.769 |
| Default | 0.682 | 0.0 | 0.938 | 0.0 | 3.0 |
이어
Table 12 Correlation
| DD | ESG | E | S | G | ROA | Tobin’s Q | Total asset | Fixed asset(%) | Leverage | Z score | Ind. leverage | Default | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DD | 1 | |||||||||||||
| ESG | 0.122*** | 1 | ||||||||||||
| E | 0.00773 | 0.817*** | 1 | |||||||||||
| S | 0.117*** | 0.935*** | 0.814*** | 1 | ||||||||||
| G | 0.140*** | 0.890*** | 0.604*** | 0.810*** | 1 | |||||||||
| ROA | 0.584*** | -0.00388 | -0.0862** | -0.00190 | 0.0140 | 1 | ||||||||
| Tobin’s Q | 0.506*** | 0.144*** | 0.125*** | 0.149*** | 0.0912*** | 0.319*** | 1 | =" | ||||||
| Total asset | 0.0481 | -0.0789** | -0.0733** | -0.0888*** | -0.0840** | 0.0334 | 0.0823** | 1 | ||||||
| Fixed asset(%) | 0.0467 | 0.0303 | 0.0669* | 0.0354 | 0.00340 | 0.0544* | -0.0257 | -0.0254 | 1 | |||||
| Leverage | -0.699*** | -0.152*** | -0.0551* | -0.118*** | -0.151*** | -0.196*** | -0.423*** | -0.0499 | 0.0104 | 1 | ||||
| Z score | -0.0663* | -0.0147 | -0.0143 | -0.0411 | 0.0212 | -0.0301 | -0.0428 | -0.0153 | -0.366*** | 0.0299 | 1 | |||
| Ind. leverage | -0.0611* | -0.598*** | -0.377*** | -0.551*** | -0.658*** | -0.0112 | 0.00346 | 0.0704** | -0.00884 | 0.0822** | -0.0253 | 1 | ||
| Default | -0.396*** | -0.239*** | -0.216*** | -0.217*** | -0.181*** | -0.0931*** | -0.306*** | -0.105*** | 0.0498 | 0.455*** | 0.0199 | 0.0334 | 1 | 〈Table 13〉 ESG & DD: All Sample |
본 분석은 다음과 같다. 먼저,
Table 13 ESG & DD: All Sample
| Variable | DD | DD | DD | DD | DD | |
|---|---|---|---|---|---|---|
| ESG | -0.001<br>(-0.3) | |||||
| E | -0.010\*\*\*<br>(-4.2) | -0.010\*\*\*<br>(-3.5) | ||||
| S | -0.004\*<br>(-1.9) | -0.006\*<br>(-1.9) | ||||
| G | 0.004\*\*<br>(2.0) | 0.010\*\*\*<br>(3.9) | ||||
| Default | 0.059<br>(0.3) | 0.089<br>(0.4) | 0.056<br>(0.2) | 0.088<br>(0.4) | 0.155<br>(0.7) | |
| Tobin's Q | 0.253\*\*\*<br>(5.6) | 0.245\*\*\*<br>(5.4) | 0.249\*\*\*<br>(5.5) | 0.247\*\*\*<br>(5.4) | 0.222\*\*\*<br>(4.8) | |
| ROA | 0.445<br>(0.8) | 0.509<br>(0.9) | 0.449<br>(0.8) | 0.451<br>(0.8) | 0.543<br>(1.0) | |
| Total asset | -0.251\*\*\*<br>(-3.5) | -0.264\*\*\*<br>(-3.7) | -0.254\*\*\*<br>(-3.6) | -0.253\*\*\*<br>(-3.6) | -0.272\*\*\*<br>(-3.8) | |
| Fixed asset(%) | 0.003<br>(0.2) | 0.005<br>(0.3) | 0.004<br>(0.2) | 0.003<br>(0.2) | 0.006<br>(0.4) | |
| Leverage | -6.259\*\*\*<br>(-21.9) | -6.254\*\*\*<br>(-22.0) | -6.247\*\*\*<br>(-21.9) | -6.265\*\*\*<br>(-22.0) | -6.249\*\*\*<br>(-22.0) | |
| Z score | 0.007\*<br>(1.9) | 0.007\*<br>(1.9) | 0.007\*<br>(1.9) | 0.007\*<br>(1.8) | 0.007\*<br>(1.8) | |
| Ind. Leverage | 22.671\*\*\*<br>(7.5) | 18.604\*\*\*<br>(7.3) | 20.525\*\*\*<br>(7.6) | 27.257\*\*\*<br>(8.9) | 24.839\*\*\*<br>(8.0) | |
| Constant | -6.141\*\*\*<br>(-3.6) | -4.012\*\*\*<br>(-2.8) | -4.970\*\*\*<br>(-3.2) | -8.677\*\*\*<br>(-5.0) | -7.489\*\*\*<br>(-4.3) | |
| Firm fixed effect | Y | Y | Y | Y | Y | |
| Time fixed effect | Y | Y | Y | Y | Y | |
| Observation | 5915 | 5915 | 5915 | 5915 | 5915 | |
| adj. R-sq | 0.737 | 0.737 | 0.737 | 0.737 | 0.738 | 〈Table 14〉 ESG & DD: Above Median Value of DD |
구체적으로 설명하면, 한국 시장에서 환경(E) 성과 개선은 여전히 ‘비용’으로 인식되는 단계인데, 탄소 저감, 친환경 설비 투자 등은 단기적으로 현금흐름을 압박하고 수익성을 떨어트리는 것으로 간주할 수 있다. 결과적으로 환경 점수 개선은 단기 유동성 측면에서 신용위험을 높이는 효과를 낳는 것이다. 뿐만 아니라 고용 안정, 복지, 안전과 같은 사회 성과(S)의 장기적 신뢰도에는 긍정적일 수 있으나, 즉각적인 재무적 수익을 창출하지 않으며 이에 따라 신용평가사가 평가하는 단기 부실 위험(DD)에 미치는 영향이 부정적이라고 할 수 있다. 반면 ESG 성과 중 부도거리를 증가시키는 요소는 지배구조(G)가 유일했는데, 이는 내부 통제, 감사 투명성, 이사회 독립성 등 지배구조(G) 요소가 기업의 대리인 비용(agency cost)을 완화하는 등 재무위험을 간접적으로 완화하는 핵심적인 비재무 요인인 것으로 분석된다.
이어 본 연구는 지배구조(G) 성과에 대한 강건성을 확인하기 위하여, 부도거리 중위수를 기준으로 재분석을 수행하였다. 이는 실제로 국내 신용평가사의 신용평가 방법론에 지배구조가 주요 요소로 고려되고 있는 현실을 고려한 것이다. 예를 들어, 한국신용평가(KIS)는 신용 평가 방법론의 주요 평가로 지배구조 리스크를 언급하고 있으며, 주요 유형으로 재무전략, 계열 구조, 경영진 구성, Compliance 및 공시 등 네 가지를 제시하고 있다(한국신용평가, 2022). 본 연구는 이 가운데 데이터 특성과 밀접한 ‘재무전략’ 유형을 강건성 기준으로 선정하였는데, 자본구조, 유동성 관리, 위험부담성향 등을 재무전략 리스크 유형이 부도거리와 밀접한 관련이 있기 때문이다. 구체적으로 살펴보면, 기업의 부도거리가 짧으면 부채비율이 높거나 단기적 현금흐름 관리가 중요하며, 투자 전략 역시 보수적으로 바뀔 수 있다.
Table 14 ESG & DD: Above Median Value of DD
| Variable | DD | DD | DD | DD | DD | |
|---|---|---|---|---|---|---|
| ESG | -0.000 (-0.1) | |||||
| E | -0.012\*\*\* (-3.4) | -0.013\*\*\* (-3.0) | ||||
| S | -0.004 (-1.1) | -0.004 (-0.8) | ||||
| G | 0.004 (1.5) | 0.010\*\* (2.5) | ||||
| Default | 0.168 (0.4) | 0.242 (0.6) | 0.170 (0.4) | 0.206 (0.5) | 0.338 (0.8) | |
| Tobin's Q | 0.196\*\*\* (3.2) | 0.191\*\*\* (3.1) | 0.192\*\*\* (3.1) | 0.189\*\*\* (3.1) | 0.173\*\*\* (2.8) | |
| ROA | 0.812 (0.9) | 0.928 (1.0) | 0.823 (0.9) | 0.822 (0.9) | 0.974 (1.0) | |
| Total asset | -0.394\*\*\* (-3.0) | -0.406\*\*\* (-3.1) | -0.394\*\*\* (-3.0) | -0.396\*\*\* (-3.0) | -0.411\*\*\* (-3.1) | |
| Fixed asset(%) | 0.013 (0.6) | 0.014 (0.6) | 0.014 (0.6) | 0.012 (0.5) | 0.013 (0.6) | |
| Leverage | -8.557\*\*\* (-16.1) | -8.602\*\*\* (-16.2) | -8.550\*\*\* (-16.1) | -8.585\*\*\* (-16.2) | -8.663\*\*\* (-16.4) | |
| Z score | 0.007 (1.3) | 0.007 (1.3) | 0.007 (1.4) | 0.007 (1.3) | 0.006 (1.2) | |
| Ind. Leverage | 33.850\*\*\* (6.5) | 28.383\*\*\* (6.4) | 31.356\*\*\* (6.6) | 38.722\*\*\* (7.4) | 35.748\*\*\* (6.8) | |
| Constant | -11.648\*\*\* (-4.1) | -8.778\*\*\* (-3.6) | -10.291\*\*\* (-4.0) | -14.326\*\*\* (-5.0) | -12.853\*\*\* (-4.5) | |
| Firm fixed effect | Y | Y | Y | Y | Y | |
| Time fixed effect | Y | Y | Y | Y | Y | |
| Observation | 3716 | 3716 | 3716 | 3716 | 3716 | |
| adj. R-sq | 0.638 | 0.639 | 0.638 | 0.638 | 0.640 | 〈Table 15〉 ESG & DD: Below Median Value of DD |
Table 15 ESG & DD: Below Median Value of DD
| Variable | 부도거리 | |||||
|---|---|---|---|---|---|---|
| ESG | -0.001 (-1.3) | |||||
| E | -0.005\*\*\* (-4.5) | -0.005\*\*\* (-4.2) | ||||
| S | -0.002\* (-1.7) | -0.003\* (-1.9) | ||||
| G | 0.002\*\* (2.0) | 0.005\*\*\* (4.3) | ||||
| Default | -0.274\*\*\* (-3.5) | -0.270\*\*\* (-3.5) | -0.273\*\*\* (-3.5) | -0.263\*\*\* (-3.4) | -0.253\*\*\* (-3.3) | |
| Tobin's Q | 0.202\*\*\* (4.1) | 0.182\*\*\* (3.7) | 0.197\*\*\* (4.0) | 0.198\*\*\* (4.1) | 0.154\*\*\* (3.1) | |
| ROA | 0.471\*\* (2.1) | 0.477\*\* (2.2) | 0.461\*\* (2.1) | 0.467\*\* (2.1) | 0.495\*\* (2.3) | |
| Total asset | 0.011 (0.5) | 0.004 (0.1) | 0.010 (0.4) | 0.013 (0.5) | 0.001 (0.0) | |
| Fixed asset(%) | 0.011 (0.9) | 0.016 (1.3) | 0.011 (0.9) | 0.011 (1.0) | 0.019 (1.6) | |
| Leverage | -1.638\*\*\* (-14.3) | -1.626\*\*\* (-14.3) | -1.635\*\*\* (-14.3) | -1.647\*\*\* (-14.4) | -1.616\*\*\* (-14.2) | |
| Z score | -0.001 (-0.4) | -0.001 (-0.3) | -0.001 (-0.4) | -0.001 (-0.3) | -0.000 (-0.1) | |
| Ind. Leverage | 6.289\*\*\* (5.5) | 5.212\*\*\* (5.4) | 6.308\*\*\* (6.2) | 8.951\*\*\* (7.5) | 8.201\*\*\* (6.9) | |
| Constant | -0.998 (-1.6) | -0.415 (-0.8) | -1.005\* (-1.8) | -2.446\*\*\* (-3.7) | -2.034\*\*\* (-3.1) | |
| Firm fixed effect | Y | Y | Y | Y | Y | |
| Time fixed effect | Y | Y | Y | Y | Y | |
| Observation | 2199 | 2199 | 2199 | 2199 | 2199 | |
| adj. R-sq | 0.452 | 0.457 | 0.452 | 0.452 | 0.463 | 〈Table 16〉 ESG & DD: Chaebols |
한편, 국내 자본시장에서 특수한 지배구조를 가진 기업 집단인 재벌은 ESG 성과가 기업 가치 등에 미치는 영향이 상이하다는 연구들이 존재한다(Lee and Cho, 2021; 이정환 외, 2022). 많은 재벌 기업은 기업 지분구조의 특성상 소유와 경영의 분리라는 기업 경영의 대원칙을 달성하기가 어렵고 이에 따라 지배구조 개선에 제약이 있는 것이 사실이라고 할 수 있다.
이에 본 연구는 〈Table 16〉
Table 16 ESG & DD: Chaebols
| DD | |||||
|---|---|---|---|---|---|
| ESG | -0.001 (-0.3) | ||||
| E | -0.007\*\* (-2.6) | -0.010\*\*\* (-3.0) | |||
| S | -0.000 (-0.1) | 0.004 (0.9) | |||
| G | 0.005 (1.3) | 0.005 (1.2) | |||
| Control | Y | Y | Y | Y | Y |
| Firm fixed effect | Y | Y | Y | Y | Y |
| Time fixed effect | Y | Y | Y | Y | Y |
| Observation | 1393 | 1393 | 1393 | 1393 | 1393 |
| adj. R-sq | 0.814 | 0.815 | 0.814 | 0.814 | 0.816 |
반면, 본 연구가 별개로 비재벌 기업의 ESG 성과와 부도거리와의 관계를 분석한 결과에 따르면 환경(E), 사회(S), 지배구조(G) 점수가 각각 반영된 모형에서 지배구조의 계수는 0.006로서 통계적으로 유의한 양(+)의 값을 갖고 있는 것으로 나타났다. 즉, 전체 표본에서 지배구조 개선이 부도거리에 미치는 효과는 많은 부분 비재벌 기업에서 발생한 효과라고 볼 수 있다. 분석 결과는 〈Table 17〉
Table 17 ESG & DD: Non-chaebols
| DD | ||||||
|---|---|---|---|---|---|---|
| ESG | 0.004 (1.6) | |||||
| E | -0.004 (-1.0) | -0.006 (-1.3) | ||||
| S | 0.001 (0.2) | -0.003 (-0.6) | ||||
| G | 0.003 (1.3) | 0.006\* (1.7) | ||||
| Control | Y | Y | Y | Y | Y | |
| Firm fixed effect | Y | Y | Y | Y | Y | |
| Time fixed effect | Y | Y | Y | Y | Y | |
| Observation | 4522 | 4522 | 4522 | 4522 | 4522 | |
| adj. R-sq | 0.726 | 0.725 | 0.725 | 0.725 | 0.726 |
4.3.2 애널리스트 커버리지 분석
본 연구는 부도거리와 애널리스트 커버리지와의 관계를 분석하고자 한다. ESG 성과와 마찬가지로, 본 연구는 기업, 시간 고정효과를 고려한 패널 회귀 모형을 통해 애널리스트 커버리지와 부도거리의 관계를 분석하였다. 분석 결과는
Table 18 Analyst Coverage & DD (without ESG)
| Variable | All | L | H | Chaebols | Non-chaebols | |
|---|---|---|---|---|---|---|
| Analyst | -0.043<br>(-0.5) | 0.156<br>(1.4) | -0.343<br>(-0.7) | 0.387***<br>(2.9) | -0.197<br>(-1.6) | |
| Default | 0.088<br>(0.3) | 0.327<br>(1.0) | 0.556<br>(1.2) | 0.704<br>(1.6) | 0.222<br>(0.6) | |
| Tobin's Q | 0.635***<br>(10.8) | 0.503***<br>(7.9) | 0.676***<br>(5.6) | 0.967***<br>(9.8) | 0.596***<br>(6.0) | |
| ROA | 1.080*<br>(1.7) | 2.251***<br>(3.2) | 0.516<br>(0.4) | 1.021<br>(1.3) | -0.235<br>(-0.2) | |
| Total asset | -0.065<br>(-1.0) | -0.080<br>(-1.2) | -0.066<br>(-0.5) | 0.013<br>(0.2) | -0.190<br>(-1.5) | |
| Fixed asset(%) | -0.069**<br>(-2.4) | -0.075**<br>(-2.4) | -0.105*<br>(-1.9) | 0.003<br>(0.0) | -0.047<br>(-1.3) | |
| Leverage | -7.598***<br>(-24.8) | -6.729***<br>(-17.8) | -8.192***<br>(-14.4) | -7.218***<br>(-17.2) | -8.491***<br>(-17.9) | |
| Z score | 0.000<br>(0.0) | 0.003<br>(0.6) | -0.006<br>(-0.9) | -0.001<br>(-0.2) | 0.006<br>(1.1) | |
| Ind. leverage | -3.107***<br>(-4.2) | -3.159***<br>(-3.7) | -3.332**<br>(-2.0) | 2.026<br>(1.4) | -4.109***<br>(-3.7) | |
| Constant | 5.738***<br>(7.4) | 4.946***<br>(5.6) | 7.170***<br>(3.1) | 2.599**<br>(2.4) | 7.571***<br>(7.3) | |
| Firm fixed effect | Y | Y | Y | Y | Y | |
| Time fixed effect | Y | Y | Y | Y | Y | |
| Observation | 3596 | 1754 | 1842 | 1589 | 2007 | |
| adj. R-sq | 0.785 | 0.838 | 0.760 | 0.829 | 0.768 |
Table 19 Analyst Coverage & DD (with ESG)
| Variable | All | L | H | Chaebols | Non-chaebols | |
|---|---|---|---|---|---|---|
| Analyst | -0.238 (-1.5) | 0.137 (0.5) | -0.732 (-1.2) | 0.202 (0.9) | -0.381 (-1.6) | |
| E | -0.008\*\* (-2.4) | -0.008\* (-1.7) | -0.009\* (-1.8) | -0.012\*\*\* (-3.1) | 0.002 (0.3) | |
| S | 0.000 (0.1) | 0.003 (0.4) | 0.003 (0.5) | 0.007 (1.3) | 0.002 (0.2) | |
| G | 0.013\*\*\* (3.0) | 0.033\*\*\* (4.0) | 0.003 (0.6) | 0.011\* (1.7) | 0.005 (0.7) | |
| Default | -0.470 (-0.8) | 0.767 (1.0) | -0.764 (-0.9) | 0.510 (0.6) | -0.954 (-1.2) | |
| Tobin's Q | 0.654\*\*\* (8.2) | 0.585\*\*\* (6.1) | 0.636\*\*\* (4.4) | 0.738\*\*\* (5.8) | 0.564\*\*\* (4.4) | |
| ROA | 3.610\*\*\* (3.5) | 3.990\*\*\* (2.6) | 2.301 (1.5) | 4.065\*\*\* (3.0) | 2.473 (1.5) | |
| Total asset | -0.158\* (-1.9) | -0.339\*\*\* (-3.7) | -0.027 (-0.1) | -0.201\*\* (-2.4) | -0.056 (-0.3) | |
| Fixed asset(%) | -0.022 (-0.3) | 0.069 (0.7) | -0.099 (-1.1) | 0.154 (1.5) | -0.164\* (-1.7) | |
| Leverage | -8.139\*\*\* (-15.0) | -7.456\*\*\* (-9.8) | -8.709\*\*\* (-10.4) | -8.109\*\*\* (-11.4) | -8.400\*\*\* (-9.4) | |
| Z score | 0.009 (0.8) | -0.006 (-0.4) | 0.025 (1.4) | 0.006 (0.4) | 0.047\* (1.9) | |
| Ind. leverage | 42.895\*\*\* (7.4) | 64.712\*\*\* (5.9) | 35.868\*\*\* (4.6) | 43.201\*\*\* (5.1) | 41.338\*\*\* (4.6) | |
| Constant | -15.517\*\*\* (-4.5) | -31.276\*\*\* (-5.2) | -9.368\*\* (-2.0) | -17.323\*\*\* (-3.6) | -13.437\*\*\* (-2.7) | |
| Firm fixed effect | Y | Y | Y | Y | Y | |
| Time fixed effect | Y | Y | Y | Y | Y | |
| Observation | 2105 | 801 | 1304 | 1004 | 1101 | |
| adj. R-sq | 0.820 | 0.877 | 0.791 | 0.844 | 0.796 | 〈Table 20〉 Carbon emission & DD |
4.3.3 탄소배출량 분석
이어 본 연구는 ESG 성과, 애널리스트 커버리지와 마찬가지로 기업 및 시간 고정효과를 고려한 패널 회귀 모형을 통해 탄소배출량과 부도거리의 관계를 분석하였다. 본 연구의 탄소 배출량은 자발적 탄소배출공시 기준으로 측정한 결과이기에 기업별 차이가 발생할 수 있다. 이에 따라 표본기간(2013-2017년)에 대해 KOSPI 시장에 상장한 상장사 중 탄소배출 정보가 있는 기업과 없는 기업의 부도거리, Tobin’s Q, ROA, 총자산, 고정자산 비율, 레버리지, 산업레버리지, 파산확률(Z score)를 계산하였다. 본 연구의 샘플을 살펴보면, 탄소 배출 정보가 존재하는 기업의 ROA 및 총자산 평균은 탄소배출 정보가 없는 기업에 비해 우수한 편이다. 부도거리 역시 탄소배출 정보가 있는 기업이 탄소배출 정보가 없는 기업보다 우수하다. Tobin’s Q 역시 탄소배출 정보가 존재하는 기업에서 우수한 성과를 보여, 비교적 규모가 크고 수익성이 높은 기업에서 탄소배출 정보를 많이 제공하는 것을 확인할 수 있다.16
Table 20 Carbon emission & DD
| Variable | All | L | H | Chaebols | Non-chaebols | |
|---|---|---|---|---|---|---|
| Carbon emission | 0.005<br>(0.1) | 0.013<br>(0.9) | -0.013<br>(-0.1) | -0.004<br>(-0.1) | -0.028<br>(-0.3) | |
| Default | 2.348*<br>(1.7) | 0.754<br>(1.5) | 1.853<br>(0.8) | 1.564<br>(1.2) | 6.625**<br>(2.1) | |
| Tobin's Q | 0.560***<br>(3.8) | 2.824***<br>(3.7) | 0.498***<br>(3.0) | 0.802***<br>(3.6) | 0.410<br>(1.6) | |
| ROA | 3.598<br>(1.5) | 2.118*<br>(1.8) | 6.419*<br>(1.9) | 5.057**<br>(2.3) | 4.479<br>(0.8) | |
| Total asset | -0.248<br>(-0.8) | 0.452<br>(1.1) | -0.184<br>(-0.4) | -0.206<br>(-0.8) | -0.640<br>(-0.8) | |
| Fixed asset(%) | -0.002<br>(-0.0) | -0.023<br>(-0.4) | 0.296<br>(0.5) | 0.023<br>(0.3) | -0.919<br>(-0.7) | |
| Leverage | -7.950***<br>(-5.3) | -3.291***<br>(-2.8) | -8.746***<br>(-4.8) | -6.096***<br>(-3.9) | -11.106***<br>(-3.4) | |
| Z score | -0.010<br>(-0.2) | 0.036<br>(0.8) | -0.024<br>(-0.5) | 0.003<br>(0.1) | -0.172<br>(-1.5) | |
| Ind. leverage | -1.094<br>(-0.5) | 2.113<br>(1.3) | -2.890<br>(-1.0) | 6.022**<br>(2.6) | -19.836***<br>(-3.3) | |
| Constant | 6.477***<br>(3.6) | -0.316<br>(-0.2) | 7.643***<br>(3.7) | 3.278**<br>(2.1) | 17.609***<br>(4.7) | |
| Firm fixed effect | Y | Y | Y | Y | Y | |
| Time fixed effect | Y | Y | Y | Y | Y | |
| Observation | 592 | 122 | 470 | 378 | 214 | |
| adj. R-sq | 0.868 | 0.750 | 0.821 | 0.906 | 0.800 |
4.3.4 논의 및 함의
상기 분석 결과를 종합하면, 개별 ESG 성과, 애널리스트 커버리지, 탄소배출량 등의 비재무 정보는 Merton(1974)의 방법론으로 측정한 부도거리와 다양한 관련성을 가지고 있으며 본 연구가 제시한 가설과 대체적으로 부합하는 것으로 나타난다.
먼저 통합 ESG 성과의 경우 기업 샘플 전반에서 유의한 결과가 나오진 않았으며, 반면 개별 환경(E), 사회(S) 성과는 부도거리와 통계적으로 유의한 음(-)의 관계를 가졌으며, 지배구조(G) 성과는 부도거리와 통계적으로 유의한 양(+)의 관계를 갖는 등 대체적으로 가설 1-1, 1-2, 1-3을 지지하는 것으로 나타났다. 다만, 국내 신용평가사의 신용평가 방법론(재무전략)에 기초하여 부도거리 중위수를 중심으로 분석한 결과, 부도거리 중위수 이상에서는 환경과 지배구조의 강건성이 부분적으로 확인되는 한편, 중위수 이하에서는 개별 ESG 성과의 강건성이 모두 뚜렷하게 확인되고 있다. 이와 같은 사실은 한국 자본시장에서는 유해물질 감축, 환경경영 강화 등으로 대표되는 환경 성과가 기업의 수익성과 신용 차원에서 부정적으로 받아들이는 것으로 해석된다. 특히, ESG 경영이 초기 단계인 우리나라 기업에는 환경(E) 성과 대신에 대량의 탄소배출량을 내는 등 단기 수익 중심 경영 방식이 기업 가치와 밀접한 관련성이 있음을 시사한다(Lee & Cho, 2021). 반면 사회(S) 성과의 경우 중위수 이상과 이하에서 강건성이 미약하게 확인되고 있는데, 이는 사회 공헌 차원에서 해석된 사회 성과가 투자자에게 모호하게 영향을 줄 수 있다는 선행연구와 부합하는 결과라고 할 수 있다(이정환 외, 2022).
한편, 재벌 기업과 비재벌 기업으로 기업 샘플을 구분했을 경우 재벌 기업에서는 환경(E) 성과, 비재벌 기업군에서는 지배구조(G) 성과의 강건성이 일정 부분 확인되고 있다. 이는 개별 ESG 성과가 재벌 기업 여부에 따라 차별적인 영향을 가지는 것으로 해석된다. 상대적으로 자산 규모가 큰 재벌 기업의 환경(E) 성과는 오히려 수익성을 저해하는 요소로 작용할 수 있으며(Lee & Cho, 2021), 반면 재벌 기업에 비하여 감시와 통제 수준이 약한 비재벌 기업의 경우 지배구조(G) 성과 개선이 기업 신뢰와 신용에 긍정적인 영향을 주는 것으로 보인다.
반면 또 다른 비재무 정보인 애널리스트 커버리지와 탄소배출량은 부도거리와 관련성이 제한적으로 확인되었다. 먼저
Ⅴ. 결 론
본 연구는 비재무적 정보의 신용위험을 판단하기 위해, 기존 신용평가사 모형 로직을 학습하여 통제한 뒤 탄소배출량, ESG 성과, 애널리스트 커버리지 등의 정보 등의 부도거리에 대한 영향을 분석하였다. 통제 변수로 사용되는 머신러닝 모형의 경우 비자발적 상장 폐지 기업에 대해 확장 분석하여 그 타당성에 대해 추가 검증하여, 분석의 신뢰도를 높였다는 특성이 있다.
본 연구의 분석 결과는 다음과 같다. 첫째, 머신러닝 기반으로 기업의 재무정보 및 거시경제 정보를 활용하여 투자 적격/비적격 등급 신용 등급을 예측해본 결과 랜덤포레스트 및 GBDT 모형과 같은 머신러닝 모형들이 전통적인 로짓 모형을 비교하였다. 두 머신러닝 모형은 또한 95% 가량의 높은 정확도를 보여 신용평가사의 신용평가를 기계학습을 통해 신용평가 등급이 없는 다른 기업에 대해 확장할 수 있는 가능성을 확인하였다. 특히 머신러닝을 통해 학습한 국내 신용 평가사의 등급 산정 로직을 기반으로 비자발적 상장폐지 기업을 분석해 본 결과, 머신러닝 모형의 설명력이 높은 것으로 나타났다. 이들 기업은 신용 등급이 부여되지 않았지만, 재무제표를 기반으로 상장 폐지 당시의 투자비적격등급 이하로의 예측확률이 평균 88%, 중위값 95% 이상의 높은 예측력을 보였다. 둘째, 이와 같은 예측(부도)확률을 통해 기존 신용평가 영역을 통제한 후 비재무 정보와 부도거리의 관계를 분석한 결과, ESG 지표, 특히 지배구조 지표가 비재벌기업을 중심으로 비교적 강건하게 확인되는 등 지배구조 개선이 부도확률을 줄이는 효과를 확인하였다. 반면 기업의 환경 성과는 재벌기업 등 몇몇 기업 샘플에 한하여 부도거리와 음(-)의 효과를 갖는 사실을 확인하였다. 애널리스트 커버리지, 탄소배출량 정보는 기업의 부도거리에 대한 설명력이 낮은 것으로 나타났다. 이는 성장성이 우수한 특정 기업군에 집중하는 애널리스트 커버리지 특성, 낮은 탄소배출권 가격으로 인한 탄소 위험 인식 부족 등으로 설명 가능하다.
본 연구의 주요 공헌점은 다음과 같다. 첫째, 본 연구는 머신러닝 모형을 도입하여 기존의 재무기반 신용 평가 모형을 보다 광범위하게 적용할 수 있는 방법론을 제시하여, 주로 채권 발행기업 위주로 한정적으로 제공되던 신용평가 관련 분석을 확장할 수 있는 프레임워크를 제시하였다. 둘째, 본 연구는 지배구조(G) 등 일부 ESG 정보가 신용 등급 평가에 고려될 만한 주요 정보가 될 수 있음을 확인하였으며, 탄소배출 정보 외 비재무 정보는 향후 대안 신용평가 모형 활용 시 추가적인 분석이 필요함을 시사하고 있다. 셋째, 본 연구는 기존에 다뤄지지 않았던 기업의 비자발적 상장 폐지 여부를 분석하여 재무적 신용위험의 영향력을 분석하였다.
1 https://www.mk.co.kr/news/economy/view/2022/03/281480/
2 https://news.mt.co.kr/mtview.php?no=2022071110284518752
3 Merton 의 모형에 따르면 부도거리 이외에 부도 확률 역시 계산될 수 있다. 그러나 부도 확률의 경우 많은 기업들이 0에 가깝게 집중되어 있음으로 일반적인 패널 회귀 분석에 사용하기는 어려운 것으로 알려져 있다.
4 신흥국의 경우 파산비율을 뜻하는 Z-점수 계산 방법은 아래와 같다. Meeampol et al.(2014)을 참고함.
$X_1$ = (유동자산 - 유동부채) / 총자산
$X_2$ = 유동이익 / 총자산
$X_3$ = EBIT / 총자산
$X_4$ = 총자본 / 총부채
5 이는 최근 회계자료로부터 상장폐지까지 기간이 1년 이상 소요된 경우를 반영한 것이다. 널리 알려진 대표적 비자발적 상장폐지 기업은 넥솔론(태양공 제조업체), 대아리드선(기초 소재), 베네데스하이텍(핸드백 제조업체), 사조해표(식음료 제조업체), 코리아오토글라스(자동차 안전유리 제조업체), 한진해운(해운업체), STX 조선해양(조선업체) 등으로 그 업종과 규모가 다양하다.
6 투자적격등급, 비투자적격등급 기업의 머신러닝 분석 결과는 지면 한계상 본 논문에 포함하지 못 하였으며, 별도 제공 가능하다.
7 랜덤포레스트 모델의 하이퍼파라미터는 다음과 같이 설정되었다. 앙상블을 구성하는 결정 트리의 개수(n_estimators)는 400개로 설정하였으며, 각 노드 분할 시 고려되는 특성의 개수(max_features)는 전체 특성 개수의 제곱근으로 설정하였다. 과적합을 방지하기 위해 트리의 최대 깊이(max_depth)는 10으로 제한하였으며, 노드 분할을 위한 최소 샘플 수(min_samples_split)는 3으로 설정하였다. 분할 기준(criterion)으로는 정보 이득을 측정하는 엔트로피(entropy)를 사용하였다. 클래스 불균형 문제를 해결하기 위해 클래스 가중치(class_weight)를 조정하였으며, 클래스 0에 대해 0.635, 클래스 1에 대해 2.347의 가중치를 부여하였다. 또한 GBDT 모델의 하이퍼파라미터의 경우, 부스팅 단계 수(n_estimators)는 300으로 설정하였으며, 각 약한 학습기의 최대 깊이(max_depth)는 7로 제한하였다. 학습률(learning_rate)은 0.01로 설정하여 각 트리의 기여도를 조절함으로써 과적합을 방지하고자 하였다. 또한, 각 부스팅 단계에서 전체 훈련 샘플의80%(subsample=0.8)를 무작위로 추출하여 사용함으로써 모델의 일반화 성능을 향상고자 하였다.
8 이 분석을 위하여 본 연구는 기업 샘플에 대하여 투자적격 등급(BBB) 이하 등급 1, 그렇지 않은 채권 등급을 0으로 구분하였으며, 전통적 로지스틱 분석 및 랜덤포레스트와 GBDT 를 사용한 머신러닝 모형의 성과 분석을 수행하였다. 변수별 중요도는 Permutation Importance 방식을 활용하였다. Permutation Importance 는 모델 예측에 있어 가장 큰 영향력이 큰 변수(Feature)를 포착하는 방법으로 꼽힌다. 본 연구는 각 머신러닝 모형 훈련 이후 Permutation Importance 를 모형별로 추출하였으며, 훈련된 모델이 특정 Feature 를 쓰지 않았을 때 이것이 성능 손실에 얼마나 큰 영향을 주는지 Feature 의 중요도를 통해 파악하였다. Permutation Importance 의 장점은 변수별 특정 Feature 를 무작위로 섞음으로써(Permutation), 특정 Feature 를 노이즈로 만드는 것이다. 이와 같은 과정을 거쳐 분석한 변수별 중요도는 특정 변수가 제외될 경우 발생하는 모형의 혼잡도 증가로 측정된다. 여기서 혼잡도는 구분된 이후 데이터 집합의 혼잡도를 의미하는데, 서로 다른 데이터가 섞여 있으면 데이터의 혼잡도 지수인 엔트로피가 높고 같은 값을 위주로 되어 있으면 혼잡도가 낮아진다. 실제 의사결정 나무 모형의 분화 역시 이러한 혼잡도 기준으로 이루어진다.
9 지면 한계상 로지스틱 모형, 랜덤 포레스트, GBDT 의 test set 예측 결과는 모두 포함하지 않았지만, 별도 제공 가능하다.
10 본 연구는 보편적으로 사용되는 랜덤 포레스트 모형을 기반으로 부실 확률을 예측하였다.
11 랜덤포레스트나 GBDT 모형은 큰 예측 성과의 차이가 나오지 않는 것을 확인하였다. 이에 따라 본 연구는 보편적으로 사용되는 랜덤 포레스트 모형을 바탕으로 부실 확률을 예측하였다. 각 모형의 부실확률 예측값 결과는 제공 가능하다.
12 비자발적 상장 폐지 기업 중에서 BBB 등급 이하로 구분되지 않는 기업은 확률 38.4%를 나타낸 삼애인더스의 경우였으며, 이는 일반적인 상황이 아닌 ‘이용호 게이트’ 관련 범죄와 연루되어 외부감사인의 의결 거절이 나온 매우 특수한 케이스로 알려져 있다. 실제로 이외의 상장폐지 기업들은 예측 확률을 고려한 경우 모두 BBB 등급 아래의 점수를 받은 것으로 확인되고 있다.
13 실제 기업 신용 등급을 이용하여 이러한 분석을 수행할 수도 있지만 채권을 한정적으로 발행하는 국내 자본시장의 상황상 표본에 많은 축소가 있는 것으로 확인된다. 신용 등급을 직접 활용한 분석에서 역시 전반적인 결론의 강건성은 확인할 수 있다.
14 ESG 등급이 존재하는 기업-회계년도 관측치 중 실제 신용 등급이 있는 기업들은 약 24.5%로서 신용 등급이 있는 기업에 대해서만 분석 수행 시 표본의 대표성에 상당한 손실을 입을 수 있다.
15 ESG 성과 점수가 0~100점 척도로 측정되는 것을 고려하면 지배구조(G) 점수가 10점 상승하면 부도거리는 약 0.10이 상승하는 것이다. 이를 부도확률(Probability of Default)로 환산하면, 부도거리가 2.0에서 2.1로 증가하면 부도확률은 2.28%에서 1.79%로 줄어든다. 이는 변화량으로 치면 ‘-0.49%p’에 해당한다. 즉, 지배구조(G) 점수가 10점 높아지면 부도확률은 약 0.5%p 낮아지는 것이다. 이는 ‘0.5%p’의 차이로 간주될 수 있지만, 자본시장에서는 BBB 와 A 등급 사이 신용 스프레드가 약 40~50bp 인 것을 고려하면 경제적으로 유의미하다고 할 수 있다.
16
17 보다 광범위한 데이터 기간과 분석범위를 가진 Trucost 탄소배출 데이터를 한국 기업에 적용해도 동일한 결론을 얻을 수 있다.